Clustering Engine Manual
for version 1.9.0
Copyright © 2002-2014 Carrot Search s.c., Stanisław Osiński, Dawid Weiss
Abstract
This manual provides detailed information about the Carrot Search Lingo3G document clustering engine. It includes a general overview of Lingo3G, a description of Lingo3G application suite, integration interfaces, attributes and configuration files.
Lingo3G Online Demo: http://search.carrotsearch.com
Table of Contents
- 1. Introduction
-
- 1.1. Features
- 1.2. Release history
-
- 1.2.1. Release 1.9.0
- 1.2.2. Release 1.8.1
- 1.2.3. Release 1.8.0
- 1.2.4. Release 1.7.1
- 1.2.5. Release 1.7.0
- 1.2.6. Release 1.6.2
- 1.2.7. Release 1.6.1
- 1.2.8. Release 1.6.0
- 1.2.9. Release 1.5.5
- 1.2.10. Release 1.5.4
- 1.2.11. Release 1.5.3
- 1.2.12. Release 1.5.2
- 1.2.13. Release 1.5.1
- 1.2.14. Release 1.5.0
- 1.2.15. Release 1.4.2
- 1.2.16. Release 1.4.1
- 1.2.17. Release 1.4.0
- 1.2.18. Release 1.3.2
- 1.2.19. Release 1.3.1
- 1.2.20. Release 1.3.0
- 1.2.21. Release 1.2.7
- 1.2.22. Release 1.2.6
- 1.2.23. Release 1.2.5
- 1.2.24. Release 1.2.4
- 1.2.25. Release 1.2.3
- 1.2.26. Release 1.2.2
- 1.2.27. Release 1.2.1
- 1.2.28. Release 1.2.0
- 1.2.29. Release 1.1.0
- 1.2.30. Release 1.0.0
- 2. FAQ
- 3. Tools and APIs
- 4. Getting started
- 5. Lexical resources
- 6. Tuning clustering
-
- 6.1. Desirable characteristics of documents for clustering
- 6.2. Tuning clustering in Lingo3G Document Clustering Workbench
- 6.3. Excluding or boosting specific clusters in the results
- 6.4. Reducing the size of the Other Topics cluster
- 6.5. Making clusters more general
- 6.6. Making clusters more specific
- 6.7. Benchmarking clustering performance
- 7. Customization
- 8. Troubleshooting
- 9. Attribute reference
- 10. Carrot2 data formats
List of Figures
- 2.1. Relationship between Carrot2 and Lingo3G
- 3.1. Lingo3G Document Clustering Workbench screenshot
- 3.2. Lingo3G Document Clustering Server quick start screen
- 4.1. Lingo3G Document Clustering Workbench XML search view
- 4.2. News feed XML to Lingo3G format transformation
- 4.3. Document attribute that contains a list of values.
- 4.4. Lingo3G Document Clustering Workbench Lucene search view
- 4.5. Lingo3G Document Clustering Workbench Solr search view
- 4.6. Setting up Lingo3G Java API in Eclipse IDE
- 5.1. Relationships between Lingo3G lexical resources
- 5.2. Debug attributes section
- 5.3. Lingo3G Document Clustering Workbench restart clustering button
- 6.1. Tuning clustering in Lingo3G Document Clustering Workbench
- 6.2. Attributes view's context menu
- 6.3. Lingo3G Document Clustering Workbench Benchmark view
- 7.1. Example Carrot2 component suite
- 7.2. Example Carrot2 attribute set
- 8.1. Lingo3G Document Clustering Workbench error dialog
- 8.2. Lingo3G Document Clustering Workbench Show View dialog
- 8.3. Lingo3G Document Clustering Workbench Error Log view
- 8.4. Lingo3G Document Clustering Workbench Event Details dialog
- 10.1. Carrot2 input XML format
- 10.2. Carrot2 output XML format
- 10.3. Carrot2 output JSON format
List of Examples
- 5.1. A sample word dictionary file
- 5.2. Simple synonym definition
- 5.3. Simple label dictionary entry
- 5.4. Single word exact matching pattern
- 5.5. Single word exact matching pattern
- 5.6. Single word leading matching pattern
- 5.7. Single word trailing matching pattern
- 5.8. Single word middle matching pattern
- 5.9. Single function word matching pattern
- 5.10. Single word anywhere matching pattern
- 5.11. Word sequence exact matching pattern
- 5.12. Word sequence leading matching pattern
- 5.13. Word sequence leading matching pattern
- 5.14. Word sequence middle matching pattern
- 5.15. Word sequence anywhere matching pattern
- 5.16. Numeric token matching pattern
- 5.17. Part of speech-based token matching patterns
- 5.18. Surface matching rules
- 5.19. Regexp matching pattern
- 5.20. Regexp matching pattern
- 5.21. Regexp matching pattern
- 5.22. Regexp matching pattern
- 5.23. Regexp matching pattern
- 5.24. A sample label dictionary file
- 5.25. A sample synonyms file
Lingo3G is a document clustering engine that can organize collections of text documents into clearly labeled thematic groups called clusters, in real-time, fully automatically and based only on the documents' content. Lingo3G's unique metaheuristic local optimum search clustering algorithm ensures that the engine delivers high-quality semantic clustering combined with fast processing and high scalability.
In most cases your workflow with Lingo3G applications would be the following:
-
Use Lingo3G Document Clustering Workbench and possibly other applications from Lingo3G application suite to see what the clustering results are like for your content. If the results are promising, you can use the Lingo3G Document Clustering Workbench to further tune the clustering algorithm's settings.
-
If you are developing Java software, use Lingo3G API and JAR to integrate clustering into your code. For non-Java environments, set-up the Lingo3G Document Clustering Server and call Lingo3G clustering using the REST protocol.
Further sections of this chapter briefly describe Lingo3G features and release history. Chapter 2 answers the most frequently asked questions about Lingo3G, it can also serve as a question-based index to the rest of this manual. Chapter 3 introduces the applications available in Lingo3G distribution, while Chapter 4 shows how to quickly set up Lingo3G to cluster your own data. Chapter 5 explains how to tune Lingo3G lexical resources (such as stop words or synonyms) and Chapter 6 deals with tuning of other attributes of the algorithm. Chapter 7 shows how to customize Lingo3G applications. Finally, Chapter 9 provides a complete Lingo3G attribute reference.
Main Lingo3G features include:
-
Quality Lingo3G delivers high-quality semantic clustering with special emphasis placed on making cluster labels meaningful, concise and varied.
-
Performance Lingo3G internal architecture was designed to ensure ultra-fast input document preprocessing and clustering. As a result, on an average desktop machine[1], Lingo3G clusters 100 search results in less than 5ms, 500 results in about 20ms and 10000 results in about 150ms.
-
Scalability Lingo3G makes it possible to cluster thousands of search results (e.g. 10.000 search results in about 530ms), as well as larger sets of full-text documents.
-
Tuning A wide range of parameters can be changed to fine-tune the results and achieve the desired balance between clustering quality and performance. For a reference of the available Lingo3G attributes, please see Section 9.1.
-
100% pure Java Exceptional performance of Lingo3G is achieved in 100% pure Java code, with no need for external platform-specific libraries. This makes it possible to embed Lingo3G in software targeted at virtually any platform supporting Java 1.6.0 or later, including Windows, Linux and Mac OS.
-
Varied integration options Java-based can access Lingo3G clustering by directly using its Java API. C# / .NET software can call Lingo3G clustering using the native C# API Other non-Java applications can call Lingo3G through the Lingo3G Document Clustering Server, which exposes the clustering as a REST service. Examples of calling the service from PHP5, C#, Ruby, Java and curl are provided. For more details about the integration options, see Section 4.3.
-
Synonyms Lingo3G makes it possible to configure a list of synonyms (word aliases), e.g. photos = pictures = pics = photographs, which can further increase the quality of clustering. For more details, please see Chapter 5.
-
Label filtering Lingo3G can boost or suppress specified words or phrases in the results in order to e.g. highlight product names or filter abusive language. For more details, please see Chapter 5.
-
Foreign language support Currently Lingo3G supports clustering in 19 languages: English, Danish, Dutch, Finnish, French, German, Hungarian, Italian, Korean, Norwegian, Polish, Portuguese, Romanian, Russian, Spanish, Swedish, Arabic (experimental) and Chinese Simplified (experimental). Lingo3G can also automatically determine the language of the clustered documents.
-
Reuse of Carrot2 Open Source project components Lingo3G seamlessly integrates with the Carrot2 framework, which enables easy reuse of a variety of components available free of charge in Carrot2. Carrot2 offers components for fetching data from search engines that provide the required APIs (for example Microsoft Bing or PubMed), as well as other sources of documents like Lucene, Apache Solr or ElasticSearch.
This section briefly summarizes the history of Lingo3G releases and the features these releases added.
The 1.9.0 release comes with support for ad-hoc lexical resources and clustering Hindi content.
New features
-
[LINGO-81]: Ad-hoc lexical resources. Starting with version 1.9.0, you can provide one-off lexical resources that will be applied on top of the built-in dictionaries for the duration of one clustering request. With ad-hoc lexical resources you will be able to implement per-user dictionaries in a multi-user application or one-off dictionaries aimed at boosting or removing certain labels from the cluster set the user is currently seeing.
Please see the Word dictionary, Label dictionary and Synonym dictionary attributes for more details. The
UsingAdHocLexicalResourcesclass in Lingo3G Java API shows how to use the ad-hoc resources from the Java API. -
[LINGO-405]: Support for clustering Hindi content Lingo3G 1.9.0 comes with initial support for clustering Hindi content.
The 1.8.1 release issues a number of issues and reverts automatic language recognition from demo applications (Workbench, DCS) (see issues LINGO-401, LINGO-396, LINGO-402 below).
Changes in functionality
-
[LINGO-401]: Language detection disabled by default. In certain cases, misrecognized language of some documents combined with the FLATTEN_ALL language aggregation strategy could lead to bad-quality cluster sets.
To ensure that Lingo3G creates high-quality clusters for typical inputs (English content) out-of-the box, the 1.8.1 release disables the by-default-enabled language recognition introduced in version 1.8.0. You can still enable language recognition manually using the Language recognition attribute. We will keep working on both improving language recognition quality for short documents and figuring out how to merge clusters from different languages into a single hierarchy better.
-
[LINGO-402]: Language aggregation strategy changed to FLATTEN_MAJOR_LANGUAGE. Lingo3G 1.8.1 changed the default language aggregation strategy from FLATTEN_ALL back to FLATTEN_MAJOR_LANGUAGE. The latter strategy will let you spot language recognition errors more easily by creating dedicated parent clusters for each of the minority languages.
-
[LINGO-375]: Improved selection of cluster label candidates. Combined with label filtering, the aggregation of synonymous phrases could prevent certain high-quality labels from appearing on output. For example, if the input text contained 10 occurrences of "Energy Efficiency" and 11 occurrences of "Energy Efficient", only the latter would have been considered as a cluster label. If the label dictionary rejected labels ending in adjectives, the concept of energy efficiency would not be present in the results at all.
Since the 1.8.1 release, both "Energy Efficiency" and "Energy Efficient" would be allowed as cluster labels, the final choice being made based on the phrase frequencies and label dictionary filtering.
-
[LINGO-396]: Non intuitive cluster ordering for multi-lingual clustering (FLATTEN_ALL). When clusters from multiple languages are flattened into a single list, the scores of clusters become incomparable and cannot be used for ordering. The default strategy for FLATTEN_ALL is now to sort by document count.
Bug fixes
-
[LINGO-400]: language recognition improvements. Minor tweaks of input normalization before language detection. These should yield some improvement in classification accuracy, in particular for odd inputs, such as ALL-UPPERCASE inputs.
Improvements
-
[LINGO-398]: Update to Carrot2 3.8.1. This release comes with updated Carrot2 (3.8.1).
The 1.8.0 release provides a bunch of new features and improvements.
New features
-
[LINGO-315]: Much improved automatic language detection Fully fledged statistical language detection covering all the languages Lingo3G supports and more. The detection should be blazing fast and is enabled by default in the Workbench, DCS and batch applications. You need to enable it manually if you use the API directly for backwards compatibility reasons.
[LINGO-391]: improved integration of label rules and Japanese segmentation The Japanese clustering component will now take into account any label image (surface) matching rules that discard cluster labels and apply the matching rules earlier in the clustering process to fetch more label candidates.
[LINGO-392]: New label surface-image matching rules A new type of matching rules was added to lexical resoures: the new type of rules matches exact surface form of a label. This can be used to boost or prevent labels from appearing. Surface rules are particularly important for languages where the internal tokenization may not be obvious (so word-based rules are hard to express). The documentation contains syntax details and performance caveats associated with the new type of rules.
Bug fixes
-
[LINGO-389]: cluster labels that included query terms could have documents without those terms This bug could manifest itself in cluster documents which contained sub-phrases (including synonyms and all other transformations) of the cluster label's phrase.
Improvements
-
[LINGO-394]: Official support for ElasticSearch. ElasticSearch is now officially supported via elasticsearch-carrot2 plugin. The manual has additional information about adding Lingo3G JARs to the plugin.
-
[LINGO-384]: the default language aggregation strategy is now FLATTEN_ALL. If the input contains multilingual documents, these documents will be clustered independently and the clusters formed in each independent process will then be merged into one tree before being returned to the user.
-
[LINGO-386]: Workbench, DCS and batch application now use language recognition by default. All demo applications now use language recognition by default in the absence of explicit language marker on input documents. This improves usability and quality, especially from the Workbench.
-
[LINGO-387]: decrease memory and on-disk footprint for Japanese preprocessing component If you're using the (optional) Japanese preprocessing component, this patch decreases the required size on disk and memory footprint.
-
[LINGO-393]: faster application of regexp label rules If you're using regular expression-based label rules, they will be applied faster now.
The 1.7.1 release provides a major bug fix to the Japanese preprocessing pipeline.
Bug fixes
-
[LINGO-383]: NullPointerException when clustering Japanese content with non-Japanese query When clustering Japanese content a query with non-English characters or other terms could be misinterpreted and result in a null pointer expression. An upgrade is advised.
The 1.7.0 release provides initial support for clustering Japanese and a number of internal tweaks to the clustering algorithm.
New features
-
[LINGO-368]: Support clustering in Japanese. Version 1.7.0 comes with an initial support for clustering documents in the Japanese language. This feature is a result of joint efforts of Carrot Search s.c. and Atilika Inc. and is optional for current Lingo3G users (the JAR can be omitted if not needed, an additional license is required to enable this feature). Contact Carrot Search for details.
Improvements
-
[LINGO-377]: Improved command-line launchers. Simple tweaks to command-line shell scripts to not request "Y" on Windows and have a consistent JVM override-options environment variable (DCS_OPTS, BATCH_OPTS, etc.).
-
[LINGO-365]: License signature updates. An update to license signing was rolled out. This does not affect existing licenses but new license keys (version 1.2) may be incompatible with Lingo3G versions before 1.7.0.
-
[LINGO-354]: Third party libraries update. Updated IKVM, Carrot2 and other third party libraries to up-to-date versions. This also includes switching to Lucene 4.x as part of Carrot2 dependency.
Bug fixes
-
[LINGO-370]: Precise document assignment incorrect for certain specific inputs. Precise document assignment may be incorrect if two different words have the same stem, but only one of the words is declared as a stop word. Precise document assignment would not be applied to clusters containing such words. In such rare cases, the cluster would contain all the documents it would have had with precise document assignment disabled. This release solves the issue by cleaning up the ambiguities in the internal dictionaries.
-
[MULTIPLE]: Maintenance branch catch-up. All issues and improvements previously rolled out to 1.6.x maintenance branch are part of 1.7.0 release as well.
The 1.6.2 release provides a major bug fix to the clustering algorithm and a number of improvements to the Lingo3G Document Clustering Workbench.
Bug fixes
-
[LINGO-356]: Precise document assignment does not work correctly. Versions prior to 1.6.2 would not correctly prune non-matching documents when requested to do so by enabling Precise document assignment. As a result, for most inputs, document-cluster assignments would be the same, regardless of whether precise document assignment was enabled or not.
Version 1.6.2 fixes this issue. Additionally, two attributes, Precise document assignment slop multiplier and Precise document assignment slop offset, were added for fine-tuning of the proximity in which label words must occur for a document to be assigned to a cluster. Please see the documentation of the Precise document assignment attribute for a detailed description of the two tuning attributes.
Improvements
-
[LINGO-959]: Decrease memory footprint for visualizations of large inputs. As of version 1.6.2 Lingo3G Document Clustering Workbench requires less memory to visualize the results of clustering large collections of long documents.
-
[LINGO-955]: Display all labels of multi-label clusters. As of version 1.6.2 Lingo3G Document Clustering Workbench and Lingo3G Web Application display all labels of mutli-label clusters, not just the highest-scoring one.
The 1.6.1 release provides minor bug fixes, added support for min/max numeric value scoring and IKVM update for the .NET release.
Improvements
-
[LINGO-353]: Min/max numeric value scoring. An attempt to use min/max numeric value scoring in version 1.6.0 would throw an
UnsupportedOperationException. Version 1.6.1 fixes this issue. -
[LINGO-350]: Required JAR missing in Solr package. Version 1.6.0 missed a required JAR in the Apache Solr package. Version 1.6.1 fixes this issue.
-
[LINGO-354]: IKVM update. The .NET version was recompiled with stable IKVM version 7.1.4532.2.
-
[LINGO-349]: Restore SOLR section in the manual. Apache Solr integration section was omitted from the 1.6.0 manual. The 1.6.1 release corrects this issue.
The 1.6.0 release provides speed and memory footprint improvements, in particular for clustering longer documents or larger document sets.
Improvements
-
[LINGO-334, LINGO-299, LINGO-337]: speed improvements and optimizations for larger inputs. Major speed improvements (30-100%) in clustering larger sets of documents (> 2k documents; or longer documents in general).
-
[LINGO-236, LINGO-298]: Refactoring of data formats to decrease memory footprint. Smaller memory footprint for core clustering algorithm (10-20%, depending on the number of documents and their length).
-
[LINGO-344, LINGO-346]: Improvements to Lingo3G.NET. Upgrade .NET binding to IKVM 7.1. Assemblies are signed to allow installation in the GAC and ahead-compilation (using ngen) for faster startup times.
-
[LINGO-303, LINGO-275]: External hints for the clustering algorithm. You can now use non-textual attributes of documents (numeric, nominal) to influence the choice of clusters. Please see the Cluster scoring fields attribute documentation for more information and usage examples.
-
Other improvements and bug fixes. Minor bug fixes and algorithm tunings. Upgrade to Carrot2 Core 3.6.0 and update of dependent libraries.
Backward incompatible changes
-
[LINGO-330]: corrected typo in an attribute's key. Corrected attribute key from: "phrase-df-theshold-scaling-factor" to "phrase-df-threshold-scaling-factor". Please review your saved algorithm attributes and modify them if this parameter was used.
The 1.5.5 release provides smaller memory footprint required for clustering and speed boosts in the core Lingo3G algorithm.
Improvements
-
[LINGO-299]: Alternative strategy of computing internal data structures. These changes to Lingo3G result in smaller required memory footprint and improved processing speed.
The 1.5.4 release fixes one minor issue related to the resolution of cyclic includes in lexical resource files.
Bug fixes
-
[LINGO-326]: Certain cyclic lexical resource includes get unresolved Previous versions of Lingo3G would ignore certain cyclic include clauses, such as when, for example,
label-dictionary.en.xmlincludeslabel-dictionary.common.xmland at the samelabel-dictionary.common.xmlincludeslabel-dictionary.en.xml. The unresolved include clauses would lead to clearly visible deterioration of cluster label quality, such as labels being or starting/ending in stop words. Release 1.5.4 fixes this issue.
The 1.5.3 release fixes one major and a number of minor issues. It also introduces an improvement in license file loading in Lingo3G C# API.
Bug fixes
-
[LINGO-321]: IllegalArgumentException occasionally thrown on Oracle JRE 7 When previous releases of Lingo3G run under Oracle JRE 7, an
IllegalArgumentExceptionmay occasionally be thrown. Release 1.5.3 fixes this issue.When upgrade to Lingo3G 1.5.3 is not possible and running Oracle JRE 7 is a priority, the workaround is to start the JVM with the -Djava.util.Arrays.useLegacyMergeSort=true option.
-
[LINGO-313]: Superfluous removal of leading and trailing function words from labels Previous releases of Lingo3G would remove leading and trailing function words from labels even in the absence of the relevant entry in the label dictionary. This may have lead to the Minimum label length not being enforced for labels starting or ending in function words. Release 1.5.3 fixes this issue.
-
[LINGO-314]: The Remove repeated synonyms from labels attribute is ignored Previous releases of Lingo3G would ignore the Remove repeated synonyms from labels and process documents as if the attribute was always set to
true. Release 1.5.3 fixes this issue.
Improvements
-
[LINGO-306]: Loading of Lingo3G license file from the location of the Lingo3G C# assembly License file can be placed in the same location as indicated by the Lingo3G assembly's
Locationproperty. Please see Section 3.8 for more details.
The 1.5.2 release fixes a number of bugs and introduces improvements in several Lingo3G tools.
Improvements
-
Ajax support in Lingo3G Document Clustering Server As of the 1.5.2 release, Lingo3G Document Clustering Server supports the
GETandPOST/x-www-form-urlencodedrequest methods, you can now call the DCS directly from your Ajax applications. The Quick Start screen will help you to generate example DCS requests using all supported methods. -
Lingo3G Document Clustering Workbench improvements Release 1.5.2 makes a number of improvements in the Lingo3G Document Clustering Workbench:
- Consistent key binding for reclustering the content of the active tab: <Ctrl>+R on Windows/Linux and ⌘+R on Mac OS.
- Expanded/collapsed branches in the cluster tree are now preserved between reclusterings.
- Separate buttons for collapsing and expanding all clusters in the cluster tree.
-
Dependency updates. Lingo3G dependencies have been updated:
-
High Performance Primitive Collections to version 0.4.1.
-
Bug fixes
-
[LINGO-283]: Minimum label length attribute is ignored Version 1.5.0 and 1.5.1 ignore the Minimum label length attribute. Version 1.5.2 fixes this issue.
-
[LINGO-297]: Incorrect occurrence count for certain phrases Versions prior to 1.5.2 would assume incorrect occurrence counts for certain phrases. Version 1.5.2 fixes the issue.
The impact of this issue on clustering results is minor as the occurrence frequency is one of many factors Lingo3G considers when choosing cluster labels. While labels of smaller clusters or subclusters produced by version 1.5.2 may slightly differ compared to previous releases, the major structure of the top-level clusters should be retained.
The 1.5.1 release fixes one bug and introduces two improvements.
Improvements
-
Lower memory consumption of precise document assignment Version 1.5.1 slightly improves the memory characteristics of the Precise document assignment feature.
-
Unobfuscated license exceptions Version 1.5.1 throws the unobfuscated
LicenseExceptionwhen license verification errors occur. With this change, the exception can be caught and properly processed in the application code.
Bug fixes
-
[LINGO-277]: Lingo3G Document Clustering Server may consume large amounts of memory for long input documents. Version 1.5.0 of Lingo3G Document Clustering Server may consume large amounts of memory when clustering long input documents. The reason for this is a misconfiguration of the internal processing results cache. Version 1.5.1 fixes this issue.
To apply the fix to Lingo3G 1.5.0 or earlier, overwrite the
WEB-INF/dcs-config.xmlconfiguration file located in thewar/lingo3g-dcs.wararchive with the following contents:<?xml version="1.0" encoding="UTF-8"?> <config cache-documents="false" cache-clusters="false" component-suite-resource="suite-dcs.xml" />
The 1.5.0 release introduces a built-in English word database for improved quality of labels, improved lexical resource management and a number of attributes for more fine-grained control of cluster labels.
New features
-
Built-in English word database. Lingo3G now ships with a large built-in database of English words that includes part-of-speech and inflection information. The database enables better filtering of potentially meaningless labels, e.g. those consisting of an individual verb or adjective. Furthermore, the database can be optionally used to perform less aggressive stemming of English words. Please see the Built-in database for label filtering and Built-in database for stemming attributes for more details.
-
FoamTree visualization. A new
 physics-inspired tree map visualization called FoamTree
is available in the Lingo3G Document Clustering Workbench.
physics-inspired tree map visualization called FoamTree
is available in the Lingo3G Document Clustering Workbench.
Improvements
-
More intelligent handling of non-sentence-ending full stop characters. Words containing non-sentence-ending full stops, dash (-) or slash (/) characters, such as Prof., e.g. or n/a, can now be declared as such in the word dictionary. The declared words will be ignored during clustering, which is likely to increase the quality of cluster labels. The default word dictionaries contain a number of common entries of such type.
-
More fine-grained control over cluster label lengths. The preferred cluster label length in words can now be suggested to Lingo3G using two new attributes: Preferred label length and Preferred label length deviation. Also, the Maximum label length can now be specified.
-
Fine-grained lexical resource merging. Syntax of the
includetag has been extended to enable better organization of lexical resource files. One use case of the new syntax is more fine-grained control over merging of lexical resources: lexical resources of arbitrary languages can now be included. As an example, theword-dictionary.common.xml, included from all other word dictionaries, contains common English, Spanish and German stop words. This ensures that these stop words will not appear as cluster labels when clustering multilingual collections of documents.The related
merge-resourcesattribute has been removed. Its function can now be achieved either by extending the common dictionaries or using explicit cross-language includes. -
Lexical resource loading improvements. Locations from which Lingo3G loads lexical resources have been made consistent with the locations used in the Carrot2 framework. Changes include:
-
Application-specific lexical resource locations. For the ease of access and modification, Lingo3G can now load lexical resources from a number of application-specific locations.
-
Discontinued support for the
resource-dirattribute. Please use the Resource lookup facade attribute instead. TheUsingCustomLexicalResourcesclass in Lingo3G Java API contains a usage example. -
Discontinued support for the
resources.dirsystem property. Please use the Resource lookup facade attribute instead, as shown in theUsingCustomLexicalResourcesclass in Lingo3G Java API.
-
-
Customization of license location. It is now possible read Lingo3G license from an arbitrary location using the License resource attribute. Please see the
UsingCustomLicenseLocationclass in Lingo3G Java API for an example. -
Dependency updates. Lingo3G dependencies have been updated:
-
Carrot2 core to version 3.5.0
-
High Performance Primitive Collections to version 0.3.3
-
Google Guava to version r08
-
Apache Commons Lang to version 2.6
-
SLF4J to version 1.6.1
-
Jackson JSON to version 1.7.4
-
Ehcache to version 1.7.2
-
Lucene to version 3.1.0
-
Apache HTTP client to version 4.1
-
Apache Commons Codec to version 1.4
-
The 1.4.2 release fixes one bug and exposes one additional attribute.
Improvements
-
Maximum word document frequency. The Maximum word document frequency has been added for filtering out very common words.
Bug fixes
-
[LINGO-210]: ArrayIndexOutOfBoundsException when used in a pooling controller. When versions 1.4.1, 1.4.0 or 1.3.2 of Lingo3G are used within a pooling controller (ControllerFactory#createPooling()), an
ArrayIndexOutOfBoundsExceptionmay occasionally be thrown during initialization or processing. All Lingo3G APIs and tools in version 1.4.1, 1.4.0 and 1.3.2 are affected by this issue. Version 1.4.2 is free from the defect.
The 1.4.1 release introduces the possibility to run Lingo3G clustering within the Apache Solr search server and fixes an issue with clustering quality in Lingo3G Java API and Lingo3G C# API.
New features
-
Lingo3G clustering in Apache Solr Version 1.4.1 introduces the possibility to run Lingo3G clustering within Apache Solr.
Bug fixes
-
[CARROT-723]: Java and C# API examples perform clustering without stemming by default. The default configuration of version 1.4.0 of Lingo3G Java API and Lingo3G C# API performs clustering without stemming, which may lead to degraded clustering quality. A drop-in upgrade from an earlier release to release 1.4.0 of Lingo3G JAR would also result in a similar clustering quality decrease.
Release 1.4.1 addresses this issue: Java and C# API perform clustering using the appropriate stemming engine, a drop-in upgrade of the Lingo3G JAR does not cause the clustering quality decrease.
Other tools, including Lingo3G Document Clustering Workbench, Lingo3G Document Clustering Server, Lingo3G Command Line Interface, Lingo3G Web Application and the Solr clustering component were not affected by this issue. For more details and a workaround for Lingo3G 1.4.0, please see CARROT-723.
The 1.4.0 release introduces a native C# / .NET API for calling Lingo3G clustering as well as a number of improvements and minor bug fixes. As of version 1.4.0, Lingo3G stops supporting Java 1.5, which reached its End of Service Life in October 2009.
New features
-
Lingo3G C# API Version 1.4.0 introduces the Lingo3G C# API, which enables seamless integration of the clustering engine into C# / .NET software without external dependencies, such as Java SDK.
Improvements
-
[LINGO-115]: Improved cluster label merging. As of version 1.4.0, Lingo3G will ensure that cluster's alternative labels do not contain phrases with overlapping vocabulary, e.g. Data Mining and Data Mining Solutions.
-
[LINGO-148]: Option for putting promoted clusters at the top of hierarchy. As of version 1.4.0, Lingo3G can ensure that promoted labels are always put at the root of the cluster hierarchy. Please see the Put promoted labels at hierarchy root attribute for more details.
-
[CARROT-682]: Dependency on Lucene API removed. Versions prior to 1.4.0 depended on Lucene 3.x API, which could cause integration problems in systems using earlier versions of Lucene. Version 1.4.0 completely removes the dependency on Lucene API and as a result, Lingo3G will not interfere with earlier and future releases of Lucene.
-
Dependency updates. A number of dependencies have been updated:
-
High Performance Primitive Collections to version 0.3.1
-
Google Collections replaced with Guava
-
SimpleXML to version 2.3.5
-
Jackson JSON to version 1.5.2
-
DOM4J dependency removed
-
Bug fixes
-
[LINGO-150]: Clustering can enter an infinite loop. Versions prior to 1.4.0 would enter an infinite loop when both Cluster-document overlap label scorer weight and Maximum top-level clustering passes were set to 0.0. Version 1.4.0 fixes this issue.
-
[LINGO-135]: Expired license at one location prevents other possibly valid licenses from being applied. In case many license files were available to Lingo3G, versions prior to 1.4.0 would allow an expired license to override a valid one, which could occasionally cause hard-to-debug problems, especially in systems with complex class paths. As of version 1.4.0, if any of the available licenses is valid, Lingo3G will accept it, disregarding the invalid license files.
The 1.3.2 release brings significant improvements in scalability of clustering of larger sets of documents as well as a number of minor Lingo3G Java API updates.
Improvements
-
[LINGO-142]: Scalability improvements. Version 1.3.2 of Lingo3G significantly improves the scalability of clustering when processing 1000 and more documents. Compared to the 1.3.1 release, processing times decreases range from 40% (18000 documents) to 80% (1000 documents). Memory usage decreases range from 3% (18000 documents) to 30% (1000 documents).
-
[LINGO-136]: Clustering of the specified document fields. Lingo3G Java API: Clustering based on the specified fields of Documents. Please see the Content fields attribute for more details.
-
[CARROT-644]: Controller Java API improvements. Lingo3G Java API: component instance pooling and data caching facilities of the CachingController have been separated. ControllerFactory can now create controllers with any combination of pooling (enabled/disabled) and caching (enabled/disabled).
-
Dependency updates. A number of dependencies have been updated:
-
Lucene to version 3.0.1
-
High Performance Primitive Collections to version 0.2.0
-
Ehcache to version 1.7.1
-
The 1.3.1 release adds support for clustering in a number of languages, including Arabic (experimental) and Korean, introduces Lingo3G command-line interface as well as a number of smaller improvements.
New features
-
[LINGO-120]: More foreign languages supported. Arabic, Danish, Finnish, Hungarian, Korean, Romanian, Swedish and Turkish have been added to the list of supported languages. Support for Arabic is experimental, which means that additional tuning of lexical resources may be needed to achieve the desired quality of results.
-
[LINGO-120]: Command Line Interface application Lingo3G Batch Processor is a new application that allows invoking clustering in batch mode through a simple command-line interface.
Improvements
-
[LINGO-119]: Optional creation of one-document clusters. Lingo3G can now, optionally, create one-document clusters. In some applications such clusters can indicate a very small but significant topic in the input documents. Creation of one-document clusters is disabled by default, use the Allow one-document clusters attribute to enable it.
-
[LINGO-126]: Simplified handling of multilingual sets of documents. Handling of multilingual collections of documents has been simplified:
-
The
multilingual-clusteringandmin-documents-for-languageattributes have been removed. Multilingual processing is now always enabled based on the declared documents' language and the Default clustering language attribute. -
The Language aggregation strategy attribute has been added to control how clusters created for different languages should be combined in the final result.
For a detailed example illustrating multilingual clustering, please see the
ClusteringNonEnglishContentclass in Lingo3G Java API. -
The 1.3.0 release brings a significant update of the Lingo3G application suite, vast simplifications of the Lingo3G Java API and clustering performance improvements.
New features
-
Lingo3G Document Clustering Workbench is a brand new GUI application for experimenting with Lingo3G clustering on data from common search engines or your own data. The Lingo3G Document Clustering Workbench enables live tuning of Lingo3G attributes, clustering performance benchmarking and attractive cluster visualizations.
-
Lingo3G Document Clustering Server offers three new features:
-
Support for document sources. As opposed to the 1.2.x line DCS, which only allowed clustering of directly uploaded XML streams, the 1.3.0 version can cluster documents coming from all document sources supported by Lingo3G, including public search engines or e.g. an instance of Apache Solr.
-
Quick start screen. The 1.3.0 version of the DCS offers a quick start screen which helps to trigger clustering directly from a web browser. The quick start screen also serves as a documentation for the request parameters and output data formats.
-
JSON-P data format. The 1.3.0 version of the DCS offers an option to output clustering results in a JSON-P format, which enables calling the DCS directly from JavaScript, regardless of the same domain origin restrictions. Please see the Parameters tab on the quick start screen for more details.
The 1.3.0 version of the DCS is compatible with the previous version, with the exception of two parameter name changes and a minor JSON output format change described below.
-
-
Simplified Lingo3G Java API. Version 1.3.0 of Lingo3G introduces a new, much simpler Java API that removes boiler-plate code. A few lines of code are enough to get a working Lingo3G clustering example. Please see Section 4.3.1 to get started with the Lingo3G Java API.
Improvements
-
Up to 66% faster clustering. Version 1.3.0 of Lingo3G provides significant improvements in the clustering performance. The table below shows speedup factors compared to version 1.2.7 [2].
Document count Speedup [a] 100 18.96% 200 12.70% 500 5.43% 1000 66.52% 2000 29.25% 5000 26.99% 10000 25.89% 20000 29.49% [a] The speedup is not monotonous with respect to the number of documents due to the adaptive thresholding controlled by the Word DF cut-off scaling and Phrase DF cut-off scaling attributes.
-
Clustering tuning tips. Some advice on tuning Lingo3G clustering has been added to this manual.
Migration from previous versions
-
XML data formats. Version 1.3.0 of Lingo3G uses the same XML data formats as previous versions, and therefore any data saved with the previous GUI tuning application will work with the Lingo3G Document Clustering Workbench and Lingo3G Document Clustering Server
-
Lingo3G Document Clustering Server request parameters. Version 1.3.0 of the DCS renames two POST request parameters:
Was (version 1.2.x) Renamed to (version 1.3.x and later) c2streamdcs.c2streamdcs.default.algorithmdcs.algorithm -
Lingo3G Document Clustering Server JSON response. In the JSON response format, the
descriptionfield (containing cluster labels) has been renamed tophrases. Additionally, all cluster attributes, such as score, are now also available in the JSON response. -
Lingo3G Java API. The Lingo3G Java API of version 1.3.x is not compatible with previous versions. Please see the code examples and JavaDoc included in the Lingo3G Java API distribution archive for invocation examples. If you have problems migrating your code to the new API, please contact Carrot Search for assistance.
The 1.2.7 maintenance release delivers two bug fixes.
Bug fixes
-
[LINGO-98] Versions prior to 1.2.7 would occasionally throw an
ArrayIndexOutOfBoundsExceptionwhen clustering with precise document assignment. Version 1.2.7 fixes this issue. -
[LINGO-108] Versions prior to 1.2.7 would throw an
ArrayIndexOutOfBoundsExceptionwhen the clustered input documents contained characters coded as 0xFFFF. Version 1.2.7 fixes this issue.
The 1.2.6 maintenance release delivers one bug fix and examples of calling REST service from PHP5.
New Features
-
[LINGO-75] To ease migration to the forthcoming version 1.3 of Lingo3G, the PHP example code calls the DCS using the REST protocol instead of XML-RPC.
Bug fixes
-
[LINGO-74] Versions 1.2.4 and 1.2.5 of Lingo3G would occasionally create subclusters containing only one document. Version 1.2.6 fixes this issue and will create only clusters with two or more documents.
The 1.2.5 maintenance release delivers three minor new features, fixes two minor bugs in the clustering engine and solves a resource locking problem when deploying Lingo3G in a web application container.
New Features
-
[LINGO-64] Lingo3G can now be set to perform an unlimited number of clustering passes that enables driving the number of unclustered documents (size of the Other Topics cluster) to a minimum. Please see the Maximum top-level clustering passes attribute for details.
-
[LINGO-63] Lingo3G can now be set to generate clusters whose labels consist of some minimum number of words. This setting may be useful to get Lingo3G to generate more specific clusters. Please see the Minimum label length attribute for details.
-
[LINGO-59] Russian has been added to the list of languages supported by Lingo3G.
Bug fixes
-
[LINGO-61] Lingo3G would handle inputs where each word had no more than 32 different inflectional forms (stems), beyond that an exception would be thrown (java.lang.RuntimeException: IntCoder.SECONDARY_INCREMENT exceeded). This limit has been removed.
-
[LINGO-60] For phrases with multiple inflection variants, Lingo3G might fail to aggregate the frequency of all variants during phrase discovery and hence underestimate the total phrase frequency. As a result, in certain conditions the phrases may not have appeared as a cluster label. The frequency underestimation problem has been solved.
-
[LINGO-55] Lingo3G would lock its lexical resources and prevent the web application from undeploying. Resource locking does not prevent the web application from undeploying anymore, provided that the
org.carrot2.core.LocalControllerBase.destroy()method is called upon destroying the handler servlet.
The 1.2.4 maintenance release adds two small features and fixes a possible ArrayIndexOutOfBoundsException.
New features
-
[LINGO-54] An option for removing repeated synonyms from labels has been added to suppress labels containing synonymous words, e.g. Nature Photos Pictures. See Remove repeated synonyms from labels for more details.
-
[LINGO-52] A parameter specifying the minimum number of documents in a cluster has been added. See Minimum cluster size form more details.
Bug fixes
-
[LINGO-53] Very rarely, when all possible single word labels are ruled out by label filters and some synonyms match are identified, an ArrayIndexOutOfBoundsException would be be thrown.
The 1.2.3 maintenance release updates the internal resource resolution mechanism.
The 1.2.1 maintenance release fixes 3 small issues discovered after the 1.2 version was made available.
Bug fixes
-
[LINGO-35] Occasionally, a NullPointerException would be thrown when initializing Lingo3G for processing of data in Polish.
-
[LINGO-44] In the application, master settings changes (made in the window available after pressing the Settings button) were not copied to individual results tabs.
-
[LINGO-43] The DirectDocumentFeedExample class contained erroneous parameter setting code — the key was not the identifier of a parameter, but its metadata.
The 1.2 release brings a number of new features in the Lingo3G suite applications, such as new sources of data [LINGO-26] and output formats [LINGO-17], as well as in the Lingo3G clustering engine itself, including accent folding [LINGO-30] and dynamic synonyms [LINGO-19].
New features
-
[LINGO-30] Support for accent folding. Now labels containing national characters (e.g. über) and their counterparts using standard ASCII characters (e.g. uber, but not ueber) will be treated as synonymous.
-
[LINGO-19] Dynamic guessing of dashed words synonyms, which automatically declares such pairs of labels as data mining and data-mining or swim wear and swimwear as synonyms. See Dashed words synonyms enabled for more details.
-
[LINGO-20] The introduction of word dictionaries (see Section 5.3) should solve the confusion around the
stopwords-unindexed.*files. -
[LINGO-28] Filtering out labels that consist only of one-letter tokens, which would remove labels like B u x, see One letter word label filter.
-
[LINGO-11] Variable query word label penalty value. Before version 1.2, Lingo3G would assign a fixed penalty for labels containing query words, which would not allow to completely remove labels containing query words. Now a parameter (see Query word label weight) can be used to explicitly set penalty for labels containing query words.
-
[LINGO-18] Setting Lingo3G parameter set id through a request-time parameter.
Bug fixes
-
[LINGO-15] Filtered-out single words don't work as synonyms. If a single word is filtered out by a label dictionary, it would not work as a synonym. E.g. if nice was not allowed as a single cluster label, declaring nice and cool as synonyms would not work.
-
[LINGO-16] Sometimes Lingo3G generates clusters containing only one subcluster labeled null
This release brings a number of new features, including: more precise document-to-cluster assignment [LINGO-4], better handling of numeric tokens [LINGO-2] and virtual merging of label dictionaries [LINGO-8]. Additionally, version 1.1 can provide a significant performance increase (up to 200%), especially for small input collections.
New features
-
[LINGO-2] Support for matching numeric tokens in label filtering (see the section called “Numeric token matching”)
-
[LINGO-3] Support for the include directive in the label dictionary file (see Section 5.5)
-
[LINGO-4] An option for more precise document-to-cluster assignment (see Precise document assignment)
-
[LINGO-6] Parameterization of the minimum size of cluster required for a subcluster creation attempt (see Minimum cluster size for subclusters)
-
[LINGO-8] Virtual merging of label dictionaries for all languages (replaced with flexible dictionary management in version 1.5.0).
Bug fixes
-
[LINGO-5] Unnecessary "Other Topics" group generated for a cluster without subclusters
-
[LINGO-7] RawDocument.PROPERTY_LANGUAGE disregarded when calling Lingo3G API
-
[LINGO-9] Switching on virtual merging of label dictionaries severely affects the performance
[1] Clustering speed measurements were done on Open Directory Project site descriptions coming from the Top/Computers category. Benchmark environment: Intel Core i7-2600K 3.4GHz, 12GB MB RAM, Windows 7. Java Virtual Machine: Sun JDK 1.7.0_04 64bit, JVM switches: -server -Xmx1024m -Xms1024m. Time presented in the table is an average of 100 runs, for each algorithm time measurement was preceded by 100 untimed warm-up runs.
[2] The benchmark was performed on a set of 20.000 Open Directory Project entries, each of which consisted of a title and a short description. The default Lingo3G attribute values were used. Benchmark environment: Intel Core2 Duo E8400 3GHz, 3GB MB RAM, Windows XP. Java Virtual Machine: Sun JDK 1.6.0, JVM switches: -server -Xmx512m.
This chapter answers the most frequently questions asked about Lingo3G. As it extensively links to further sections of the manual, it can also be treated as some sort question-based index for this manual.
|
Can Lingo3G crawl my website? |
|
|
No. Lingo3G can cluster documents or search results coming from an existing document index or search engine. You can use an Open Source project called Nutch to crawl your website. |
|
|
How does Lingo3G clustering scale with respect to the number and length of documents? |
|
|
The most important characteristic of Lingo3G to keep in mind is that it performs in-memory clustering. For this reason, as a rule of thumb, Lingo3G should successfully deal with up to a few tens of thousands of documents. The exact limit is usually application-specific. |
|
|
Can I force Lingo3G to cluster my documents to some predefined clusters / labels? |
|
|
No. Assigning documents to a set of predefined categories is a problem called text classification / categorization and Lingo3G was not designed to solve it. For text classification components you may want to see the LingPipe project. |
|
|
What is Carrot2 and how does it relate to Lingo3G? |
|
|
Carrot2 is an open source search results clustering engine created and maintained by the creators of Lingo3G. Apart from two specialized clustering algorithms, Carrot2 offers:
Lingo3G seamlessly plugs into Carrot2 and extends it with a very fast and tunable hierarchical clustering algorithm. While Lingo3G remains a proprietary piece of software, all Carrot2 components and applications it plugs into are open source and can be re-used free of charge. Figure 2.1 summarizes the relationship between Carrot2 and Lingo3G. |
|

|
What is the most suitable content for clustering in Lingo3G? |
|
|
Please see Section 6.1 for the answer. |
|
|
How can I remove meaningless cluster labels? |
|
|
Occasionally, Lingo3G may create meaningless cluster labels like read or site. Please see Chapter 5 for information on how to remove them. |
|
|
How do I minimize the size of the Other Topics group? |
|
|
Please see Section 6.1 for the answer. |
|
Lingo3G comes with a suite of tools and APIs that you can use to quickly set up clustering on your own data, tune clustering results, call Lingo3G clustering from your Java or C# code or access Lingo3G clustering as a remote service.
Lingo3G distribution contains the following elements:
-
Lingo3G Document Clustering Workbench which is a standalone GUI application you can use to experiment with Lingo3G clustering on data from common search engines or your own data,
-
Lingo3G Java API for calling Lingo3G document clustering from your Java code,
-
Lingo3G C# API for calling Lingo3G document clustering from your C# or .NET code,
-
Lingo3G Document Clustering Server which exposes Lingo3G clustering as a REST service,
-
Lingo3G Command Line Interface applications which allow invoking Lingo3G clustering from command line,
All Lingo3G applications require a license file to run. You should have received your license file from Carrot Search separately by e-mail.
Lingo3G Document Clustering Workbench is a standalone GUI application you can use to experiment with Lingo3G clustering on data from common search engines or your own data.
You can use Lingo3G Document Clustering Workbench to:
-
Quickly test Lingo3G clustering with your own data. Please see Chapter 4 for instructions for the most common scenarios.
-
Fine tune Lingo3G clustering algorithms' settings to work best with your specific data. Please see Chapter 6 for more details.
-
Run simple performance benchmarks using different settings to predict maximum clustering throughput on a single machine. Please see Section 6.7 for details.
Lingo3G Document Clustering Workbench features include:
-
Various document sources included. Lingo3G Document Clustering Workbench can fetch and cluster documents from a number of sources, including major search engines, indexing engines (Lucene, Solr) as well as generic XML feeds and files.
-
Live tuning of clustering algorithm attributes. Lingo3G Document Clustering Workbench enables modifying clustering algorithm's attributes and observing the results in real time.
-
Performance benchmarking. Lingo3G Document Clustering Workbench can run simple performance benchmarks of Lingo3G clustering algorithms.
-
Attractive visualizations. Lingo3G Document Clustering Workbench comes with two visualizations of the cluster structure, one developed within the Lingo3G project and another one from Aduna Software.
-
Modular architecture and extendability. Lingo3G Document Clustering Workbench is based on Eclipse Rich Client Platform, which makes it easily extendable.

To run Lingo3G Document Clustering Workbench:
-
Download and install Java Runtime Environment (version 1.6.0 or newer) if you have not done so.
-
Contact Carrot Search for the Lingo3G evaluation package, download the Lingo3G Document Clustering Workbench distribution archive appropriate for your operating system and extract it to some local disk location. Install the evaluation license file if you have not done so before.
-
Run lingo3g-workbench.exe (Windows) or lingo3g-workbench (Linux).
The Lingo3G Java API package contains Lingo3G JAR files along with all dependencies, JavaDoc API reference and Java code examples. You can use this package to integrate Lingo3G clustering into your Java software. Please see Section 4.3.1 and Section 4.3.2 for instructions.
The Lingo3G C# API package contains all DLL libraries required to run Lingo3G, C# API reference and code examples. You can use this package to integrate Lingo3G clustering into your C# / .NET software. Please see Section 4.3.3 for instructions.
Lingo3G Document Clustering Server (DCS) exposes Lingo3G clustering as a REST service. It can cluster documents from an external source (e.g. a search engine) or documents provided directly as an XML stream and returns results in XML or JSON formats.
You can use Lingo3G Document Clustering Server to:
-
Integrate Lingo3G with your non-Java software.
-
Build a high-throughput document clustering system by setting up a number of load-balanced instances of the DCS.
Lingo3G Document Clustering Server features include:
-
XML and JSON response formats. Lingo3G Document Clustering Server can return results both in XML and JSON formats. JSON-P (with callback) is also supported.
-
Various document sources included. Lingo3G Document Clustering Server can fetch and cluster documents from a large number of sources, including major search engines and indexing engines (Lucene, Solr).
-
Direct XML feed. Lingo3G Document Clustering Server can cluster documents fed directly in a simple XML format.
-
PHP and C# examples included. Lingo3G Document Clustering Server ships with ready-to-use examples of calling Lingo3G DCS services from PHP (version 5), C#, Ruby, Java and curl.
-
Quick start screen. A simple quick start screen will let you make your first DCS request straight from your browser.

To run Lingo3G Document Clustering Server:
-
Download and install Java Runtime Environment (version 1.6.0 or newer) if you have not done so.
-
Contact Carrot Search for the Lingo3G evaluation package, download the Lingo3G Document Clustering Server distribution archive and extract it to some local disk location. Install the evaluation license file if you have not done so before.
-
Run dcs.cmd (Windows) or dcs.sh (Linux).
-
Point your browser to
http://localhost:8080for further instructions. -
See the
examples/directory in the distribution archive for PHP, C#, Ruby and Java code examples.
Tip
If you need to start the DCS at a port different than 8080, you can use the
-port option:
dcs -port 9090
Tip
To deploy the DCS in an external servlet container, such as Apache Tomcat, use
the lingo3g-dcs.war file from the war/
folder of the DCS distribution.
Lingo3G Command Line Interface (CLI) is a set of applications that allow invoking Lingo3G clustering from the command line. Currently, the only available CLI application is Lingo3G Batch Processor, which performs Lingo3G clustering on one or more files in the Carrot2 XML format and saves the results as XML or JSON. Apart from clustering large number of documents sets at one time, you can use the Lingo3G Batch Processor to integrate Lingo3G with your non-Java applications.
To run Lingo3G Batch Processor:
-
Download and install Java Runtime Environment (version 1.6.0 or newer) if you have not done so.
-
Contact Carrot Search for the Lingo3G evaluation package, download the Lingo3G Command Line Interface distribution archive and extract it to some local disk location. Install the evaluation license file if you have not done so before.
-
Run batch.cmd (Windows) or batch.sh (Linux) for an overview of the syntax. The Lingo3G Batch Processor ships with two example input data sets located in the
input/directory. Below is a list of some common example invocations.-
To cluster one or more input files, specify their paths:
batch input/data-mining.xml input/seattle.xml
Clustering will be performed using the default clustering algorithm and the results in the XML format will be saved to the
outputdirectory relative to the current working directory. -
You can also cluster files from one or more directories:
batch input/
Each directory will be processed recursively, i.e. including subdirectories. For each specified input directory, a corresponding directory with results will be created in the output directory.
-
To save results in the non-default directory, use the
-ooption:batch input/ -o results
-
To repeat the input documents on the output, use the
-doption:batch input/ -d
-
To save the results in JSON, use the
-f JSONoption:batch input/ -f JSON
-
To use a different clustering algorithm, use the
-aoption followed by the identifier of the algorithm:batch input/ -a url
To see the list of available algorithm identifiers, run the application without arguments.
-
In case of processing errors, you can use the
-voption to see detailed messages and stack traces.
-
As of version 1.4.x of Apache Solr, Lingo3G clustering can be performed directly within Solr by means of the Solr Clustering Component.
To install Lingo3G clustering in Solr 3.2.x, 3.3.x, 3.4.x, 3.5.x, 3.6.x, 4.0 or 5.0:
-
Contact Carrot Search to obtain the Lingo3G evaluation package, download the Lingo3G Solr Compatibility Package appropriate for your version of Solr.
-
Install the license file if you have not done so before.
-
Remove the following files from your Solr installation:
- contrib/clustering/lib/carrot2-core-3.5.0.jar
- contrib/clustering/lib/hppc-0.3.4-jdk15.jar
-
Copy the contents of the Lingo3G Solr Clustering Component archive over the Solr home directory.
To enable Lingo3G clustering in any version of Solr:
-
Open
solrconfig.xmlfor editing. In thesearchComponentsection, change the value of thecarrot.algorithmproperty tocom.carrotsearch.lingo3g.Lingo3GClusteringAlgorithm.To enable the output of subclusters, change the value of the
carrot.outputSubClustersproperty, located in the clusteringrequestHandler, totrue.If your Solr instance is running multiple Solr cores, apply the above changes to
solrconfig.xmlfiles of each of the cores. -
Start Solr with the
solr.clustering.enabledsystem property set totrueto enable the clustering plugin. Clustering should be performed by the Lingo3G algorithm.
Tip
The Solr Clustering Component wiki page contains more information on configuring and running search results clustering within Solr, including a detailed description of the configuration options and the installation procedure for Apache Tomcat deployments.
Lingo3G search results clustering can be performed directly in ElasticSearch by installing a dedicated elasticsearch-carrot2 plugin. Generic plugin's installation instructions are described in detail at the plugin's GitHub web site. The API's documentation is dynamically rendered once installed (see installation instructions).
The following actions need to be taken once the baseline plugin is installed to add clustering support using the Lingo3G algorithm.
-
Copy the required JARs from Lingo3G distribution to:
${es.home}/plugins/carrot2. If minor version conflicts occur, prefer Lingo3G's version.-
lingo3g-*.jar
-
morfologik-*.jar
-
(optionally) lingo3g-japanese-*.jar and any other JARs for non-English languages if needed.
Important
It is recommended that Lingo3G version with a matching distribution of Carrot2 libraries is always used to avoid JAR dependency conflicts that may be a nighmare to debug. Minor versions should not be a problem but major revision change is very likely not to work properly.
-
-
Place the license file somewhere where the algorithm can pick it up (see Section 3.8).
-
If you have customized algorithm settings (for example exported from the Workbench), these can be placed under
${es.home}/config/lingo3g-attributes.xml. They will be picked up automatically. -
If you have any custom lexical resources then the override folder is
${es.home}/config/by default. So, for example, placingword-dictionary.en.xmlthere will override the default English word dictionary.
Once ES node is started it should log something like:
[2013-07-01 22:40:16,938][INFO ][plugin.carrot2 ] [Nox] Resources dir: c:\Users\dweiss\Downloads\elasticsearch-0.90.2\config\. [2013-07-01 22:40:17,149][WARN ][lingo3g.ck ] Japanese support not licensed or available in classpath. [...] [2013-07-01 22:40:17,517][INFO ][plugin.carrot2 ] [Nox] Available clustering components: lingo3g, lingo, stc, kmeans, byurl
Which means Lingo3G will be the first (default) algorithm to use for clustering search results. If case no errors are present the plugin's documentation and examples will also run with Lingo3G by default.
In order to run any of Lingo3G applications, you will need an XML license file, which you should have received from Carrot Search separately by e-mail.
The license file should be named license.xml
or c2license.xml, you can place it at the following
alternative locations:
-
User home directory
-
Windows: in the
c:\Documents and Settings\user\orc:\Users\user\folder -
Linux: in the
/home/userfolder -
Mac OS: drag and drop the license file to your home directory
-
-
Java system property. When you need to place the license file in some other location, you can point Lingo3G to it using the
licenseJava system property. Note that Java system properties are not equivalent to environment variables and passing a Java system property will require minor adjustments to the launching scripts, e.g. (only relevant fragment shown):java -Dlicense=/home/user/my-license.xml [...]
-
Application home directory, in the same folder as the
*.cmd,*.exeor*.shfiles that start the applications. -
Classpath. License file can be placed at the top of the classpath reachable to Lingo3G. When embedding Lingo3G in a Java/Servlet web application, put the license file in the
/WEB-INF/classesfolder of the web application.
When embedding Lingo3G in a C# / .NET application using the Lingo3G C# API, you can make the license file available from the following locations:
-
User home directory (see above)
-
Application home directory (see above)
-
Lingo3G assembly location License file can be placed in the same location as indicated by the Lingo3G assembly's
Locationproperty. This will not work for assemblies loaded from the network or byte streams. -
Embedded assembly resource License file can be embedded as a resource named
license.xmlorc2license.xmlin any executable or assembly linking to Lingo3G. See the provided examples forcscconfiguration with resource embedding.Important
Microsoft Visual Studio automatically prepends EmbeddedResource names with the project's default namespace and project-relative path. To enforce a fixed logical resource name, modify the project's msbuild
csprojfile and add:<EmbeddedResource Include="license.xml"> <LogicalName>license.xml</LogicalName> </EmbeddedResource>
This chapter will show you how to use Lingo3G in a number of typical scenarios such as trying clustering on your own documents or integrating Lingo3G with your software.
All Lingo3G applications require Java Runtime Environment version 1.6.0 or later. The Lingo3G Document Clustering Workbench is distributed for Windows, Linux 32-bit and 64-bit versions and Mac OS x86.
The Lingo3G C# API package requires the .NET Framework version 3.5 or later; it does not require a Java Runtime Environment.
This section shows how to apply Lingo3G clustering on documents from various sources.
To try Lingo3G clustering on results from search engines (such as Microsoft Bing), you can either:
or
-
Use the Lingo3G Document Clustering Workbench which can fetch and cluster documents from the same search engines as the Lingo3G Web Application
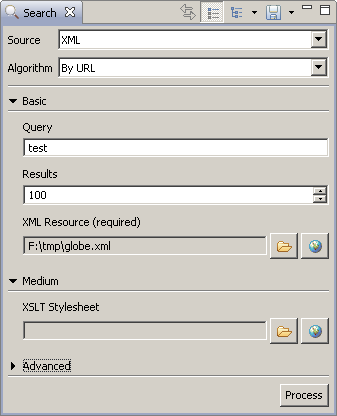
To try Lingo3G clustering on documents or search results stored in a single XML file you can use the Lingo3G Document Clustering Workbench.
-
In the Search view of Lingo3G Document Clustering Workbench, choose XML source.
-
Set path to your XML file in the XML Resource field.
-
(Optional) If your file is not in Carrot2 format, create an XSLT style sheet that transforms your data into Carrot2 format, see Section 4.2.3 for an example. Provide a path to your style sheet in the XSLT Stylesheet field in the Medium section.
-
If you know the query that generated the documents in your XML file, you can provide it in the Query field, which may improve the clustering results. Press the Process button to see the results.
To try Lingo3G clustering on documents or search results fetched from a remote XML feed, you can use the Lingo3G Document Clustering Workbench. As an example, we will cluster a news feed from BBC:
-
In the Search view of Lingo3G Document Clustering Workbench, choose XML source.
-
Set URL to your XML feed in the XML Resource field. Optionally, the URL can contain two special place holders that will be replaced with the Query and Results number you set in the search view.
In our example, we will use the BBC News RSS feed.
-
Create an XSLT style sheet that will transform the XML feed into Carrot2 format. For the news feed we can use the stylesheet shown in Figure 4.2. To add more colour to our results, the XSLT transform extracts thumbnail URLs from the feed and passes them to Lingo3G in a special attribute. Attributes that are a sequence of values can be embedded as shown in Figure 4.3.
-
Provide a path to the transformation style sheet in the XSLT Stylesheet field in the Medium section.
-
Press the Process button to see the results.
Figure 4.2 News feed XML to Lingo3G format transformation
<?xml version="1.0" encoding="UTF-8"?>
<xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:media="http://search.yahoo.com/mrss">
<xsl:output indent="yes" omit-xml-declaration="no"
media-type="application/xml" encoding="UTF-8" />
<xsl:template match="/">
<searchresult>
<xsl:apply-templates select="/rss/channel/item" />
</searchresult>
</xsl:template>
<xsl:template match="item">
<document>
<title><xsl:value-of select="title" /></title>
<snippet>
<xsl:value-of select="description" />
</snippet>
<url><xsl:value-of select="link" /></url>
<xsl:if test="media:thumbnail">
<field key="thumbnail-url">
<value type="java.lang.String"
value="{media:thumbnail/@url}"/>
</field>
</xsl:if>
</document>
</xsl:template>
</xsl:stylesheet>
To try Lingo3G clustering on documents from a local Lucene index, you can use Lingo3G Document Clustering Workbench:
-
In the Search view of Lingo3G Document Clustering Workbench, choose Lucene source.
-
Choose the path to your Lucene index in the Index directory field.
-
In the Medium section, choose fields from your Lucene index in at least one of Document title field and Document content field combo boxes.
-
Type a query and press the Process button to see the results.

To try Lingo3G clustering on documents from an instance of Apache Solr, you can use Lingo3G Document Clustering Workbench:
-
In the Search view of Lingo3G Document Clustering Workbench, choose Solr source.
-
In the Advanced section, provide the URL at which your Solr instance is available in the Service URL field.
-
In the Medium section, provide fields that should be used as document title, content and URL (optional) in the Title field name, Summary field name and URL field name field, respectively.
-
Type a query and press the Process button to see the results.

To save doocuments and/or clusters produced by Lingo3G for further processing:
-
Use Lingo3G Document Clustering Workbench to perform clustering on documents from the source of your choice.
-
Use the File > Save as... dialog to save the documents and/or clusters into a file in the Carrot2 XML format.
Tip
Saving documents into XML can be particularly useful when there is a need to capture the output of some remote or non-public document source to a local file, which can be then passed on to someone else for further inspection. Documents saved into XML can be opened for clustering within Lingo3G Document Clustering Workbench using the XML document source.
The easiest way to integrate Lingo3G with your Java programs is to use the Lingo3G Java API package:
-
Contact Carrot Search for the Lingo3G evaluation package, download the Lingo3G Java API distribution archive and extract it to some local disk location. Install the evaluation license file if you have not done so before.
-
Make sure that all JARs from the
lib/directory are available in the classpath of your program. -
Look in the
examples/directory for some sample code. Good places to start areClusteringDocumentListandClusteringDataFromDocumentSources. For a complete description of Lingo3G Java API, please see Javadoc documentation in thejavadoc/directory. -
You can use the
build.xmlAnt script to compile and run code from theexamples/directory.Tip
For easier experimenting with Lingo3G Java API, you may want to set up a Lingo3G project in Eclipse IDE.
Lingo3G Java API examples can be easily set up in Eclipse IDE. The description below assumes you are using Eclipse IDE version 3.4 or newer.
-
Contact Carrot Search for the Lingo3G evaluation package, download the Lingo3G Java API distribution archive and extract it to some local disk location. Install the evaluation license file if you have not done so before.
-
In your Eclipse IDE choose File > New > Java Project.
-
In the New Java Project dialog (Figure 4.6), type name for the new project, e.g.
lingo3g-examples. Then choose the Create project from existing source option, provide the directory to which you unpacked the Lingo3G Java API archive and click Finish. -
When Eclipse compiles the example classes, you can open one of them, e.g.
ClusteringDocumentListand choose Run > Run As > Java Application. The output of the example program should be visible in the Console view.

The easiest way to integrate Lingo3G with your C# / .NET programs is to use the Lingo3G C# API package:
-
Make sure you have .NET framework version 3.5 or later installed in your environment.
-
Contact Carrot Search for the Lingo3G evaluation package, download the Lingo3G C# API distribution archive and extract it to some local disk location. Install the evaluation license file if you have not done so before.
-
Compile example code based on the provided msbuild project file:
CD examples C:\Windows\Microsoft.NET\Framework\v4.0.30319\msbuild Lingo3G.Examples.csproj
-
Try running the executable files generated in the
examples\folder.
Tip
The provided msbuild project is not directly compatible with Visual Studio To create a Lingo3G project in Visual Studio, import the example source code and all the referenced DLLs to an existing or newly created project.
To integrate Lingo3G with your non-Java system,
you can use the Lingo3G Document Clustering Server, which exposes Lingo3G clustering as a REST/XML service. Please
see Section 3.4.1 for installation instructions and
the examples/ directory in the distribution archive for
example code in PHP, C# and Ruby.
Lingo3G clustering requires a number of JAR files to run.
The required JARs are available in the lib/required/
folder of the Lingo3G Java API package. Some of the JARs may not be required
in certain specific situations:
-
ehcache-common Required only if using the caching controller.
-
log4j, slf4j-log4j Required only if using the Log4j logging framework. If your code uses a different logging framework, add a corresponding SLF4J binding to your classpath.
A number of optional JARs can be used optionally to increase the quality of clustering in certain languages or fetch search results from external sources. The purpose of the optional JARs is the following:
-
commons-codec, httpclient, httpcore, httpmime Used by document sources that fetch results from remote search engines, such as YahooDocumentSource or YahooDocumentSource.
-
lucene-core, lucene-highlighter, lucene-memory Used by the LuceneDocumentSource.
-
rome, rome-fetcher, jdom Used by the OpenSearchDocumentSource.
-
lucene-analyzers, lucene-smartcn Required for clustering Chinese content.
-
lucene-analyzers Required for clustering Arabic content.
To improve the quality of cluster labels, Lingo3G uses a number of language-specific user-defined lexical resources: synonym, word and label dictionaries. Additionally, Lingo3G comes with a number of generic built-in lexical resources for some languages. Figure 5.1 outlines the relationships between various lexical resources in Lingo3G.

- Built-in part of speech (POS) database
-
Provides information about the part of speech (noun, verb, preposition etc.) of individual words. This information can be used in the user-defined label dictionary to prevent Lingo3G from e.g. creating labels that start or end in a preposition (e.g. Information about) or to boost labels that contain information-rich words, such as proper nouns.
Currently, a built-in POS database is only available for English.
- User-defined word dictionary
-
Complements or overrides the part of speech information provided by the built-in POS database. For languages for which the POS database is not available, the user-defined word dictionary is the only source of part of speech information.
Lingo3G comes with the default word dictionaries for the following languages: English, Danish, Dutch, Finnish, French, German, Hungarian, Italian, Korean, Norwegian, Polish, Portuguese, Romanian, Russian, Spanish, Swedish, Arabic and Chinese Simplified.
- User-defined synonym dictionary
-
Provides information about sets of words or phrases (e.g. photo, photograph, pic and picture) that have the same meaning and should be treated as synonymous during clustering.
- User-defined label dictionary
-
Provides information about specific words or phrases Lingo3G should or should not choose as cluster labels. For example, the default label dictionary excludes labels that start or end in a preposition or a verb and boosts labels that contain a proper noun. The label dictionary entries can also reference specific words to e.g. boost product names or rule out abusive language.
- Built-in stemmer / word inflection database
-
Stemmers or word inflection databases transform various form of a word to one common root. This is required to make sure that a cluster labeled e.g. Programming contains documents referencing all variants of the word, such as programs, programmer or programmed.
Lingo3G comes with built-in stemmers for the following languages: English, Danish, Dutch, Finnish, French, German, Hungarian, Italian, Norwegian, Polish, Portuguese, Romanian, Russian, Spanish and Swedish.
Additionally, Lingo3G also comes with a word inflection database for English, which can be used instead of the algorithmic stemmer. For a discussion of the differences between the two, please see the Built-in database for stemming attribute.
The user-define Lingo3G lexical resources are placed at the following application-specific locations:
- Lingo3G Batch Processor
-
Lexical resources are placed in the
resourcesfolder under the distribution folder. - Lingo3G Java API
-
Lexical resources are placed in the
resourcesfolder under the distribution folder. TheUsingCustomLexicalResourcesclass demonstrates how to configure controllers to use a given path for loading lexical resources. - Lingo3G Web Application
-
Lexical resources are placed in the
WEB-INF/resourcesfolder of the web application archive (WAR) file. - Lingo3G Document Clustering Server
-
Lexical resources are placed in the
WEB-INF/resourcesfolder of the DCS' web application archive (WAR) file. The WAR file is located in thewar/folder under the distribution folder. - Lingo3G Document Clustering Workbench
-
Lexical resources are extracted to the workspace folder on first launch. The workspace folder is typically under the Workbench's distribution directory, unless its location is modified by the
-dataoption is passed to the workbench launcher at startup. - Lingo3G core JAR file
-
Lexical resources are placed at the root of the JAR file. The default lookup location for the lexical resource factory is to scan context class loader's resources and typically (if no other class loader or location that precedes the core JAR contains such resources) these resources will be used by the implementation. Lingo3G Java API contains an example called
UsingCustomLexicalResourcesthat demonstrates ways of overriding the default location. - Lingo3G C# API
-
Lexical resources are embedded in the core assembly. At runtime, all assemblies present in the stack trace of the thread initializing the clustering controller (and thus a certain clustering algorithm) are scanned for resources (the defaults are always scanned last). An example class named
UsingCustomLexicalResources, that is provided as part of Lingo3G C# API distribution, demonstrates ways of overriding the default lexical resource search locations from .NET. - Apache Solr clustering plugin
-
The plugin tries to load the lexical resources from the
{solr.home}/conf/clustering/carrot2directory. If a resource is not found in the directory, the default version of the resource is loaded from Lingo3G JAR.A different location of lexical resources can be provided using the carrot.lexicalResourceDir Solr parameter. In particular, an absolute path can be provided to share the same lexical resources between multiple Solr cores.
The easiest way to tune the lexical resources is to use the Lingo3G Document Clustering Workbench which will allow observing the effect of the changes in real time. To tune the lexical resources in Lingo3G Document Clustering Workbench:
-
Start Lingo3G Document Clustering Workbench and run some query on which you'll be observing the results of your changes.
-
Go to the
workspace/directory which is located in the directory to which you extracted Lingo3G Document Clustering Workbench. Modify lexical resource files as needed and save changes. -
Open the Attributes view and use the view toolbar's
 button to group the attributes by semantics. In the Preprocessing
section, make sure the Processing language is correctly set and
check the Reload resources checkbox. Doing the latter
will let you to see the updated clustering results without restarting Lingo3G Document Clustering Workbench
every time you save the changed lexical resource files.
button to group the attributes by semantics. In the Preprocessing
section, make sure the Processing language is correctly set and
check the Reload resources checkbox. Doing the latter
will let you to see the updated clustering results without restarting Lingo3G Document Clustering Workbench
every time you save the changed lexical resource files.
-
To re-run clustering after you've saved changes to the lexical resource files, choose the Restart Processing option from the Search menu, or press Ctrl+R (Command+R on Mac OS).


Using a word dictionary, you can provide Lingo3G with some extra knowledge about single words, e.g. information about the part of speech (noun, verb, function word) they represent. This information can be referenced by the label dictionary entries (see Section 5.4.2) to filter out poorly-formed labels, such as starting or ending in function words, or boost labels containing information-rich words, such as proper nouns.
If a built-in part of speech database is available for the language, the definition found in the user-defined word dictionary completely overrides the information from the built-in POS database.
Word dictionaries are specified in XML files named according to the following pattern:
word-dictionary.language-code.xml,
where language-code is the
ISO-639 code of the language for which this dictionary should be used,
e.g. en for English. A sample word dictionary
file is shown in Example 5.1.
Example 5.1 A sample word dictionary file
<?xml version="1.0" encoding="UTF-8"?>
<word-dictionary>
<include base-name="domain-specific-words" />
<!-- Function words -->
<w pos="f">a</w>
<w pos="f">about</w>
<w pos="f">above</w>
<w pos="fv">have</w>
<!-- Common verbs -->
<w pos="v">go</w>
<w pos="v">allows</w>
<w pos="v">enables</w>
<!-- Common nouns -->
<w pos="n">website</w>
<!-- Phrase separators -->
<w pos=".">e.g.</w>
<!--
... more entries here
-->
</word-dictionary>
A word dictionary consists of <w> elements corresponding to individual
words. The pos attribute of the <w> element specifies one or more parts
of speech the word represents and can contain the following characters:
-
f— function word in any form, e.g. about or have -
v— verb in any form, e.g. have or allows -
n— noun in any form, e.g. website or test -
j— adjective in any form, e.g. cool -
e— adverb in any form, e.g. fully -
g— geographical term in any form, e.g. London -
p— proper noun in any form, e.g. John -
.— phrase separator, such as e.g. or ie. Lingo3G will remove phrase separators for processing and therefore will not allow them to appear in cluster labels at all.
Tip
The default label dictionary shipped with Lingo3G uses the part of speech information in the following way:
-
filters out labels being, starting or ending in a function word or verb,
-
filters out labels being or ending in an adjective or adverb,
-
slightly boosts labels containing proper nouns or geographic terms.
This default behaviour can be customized by editing the
label-dictionary.custom.xml dictionary file.
Important
Please note that although words provided in the word dictionary will be handled in a case insensitive manner, they will otherwise be taken literally, i.e. no further processing, such as stemming will be applied. As a result, in order to declare that all have, has and having are function words, three entries corresponding to these words are required.
Tip
You can split a large word dictionary into smaller parts using the
include tag, see Section 5.7.
Synonyms and label dictionaries are also specified as XML files. Example 5.2 shows an example specification that declares that words photo, photograph, pic and picture should be treated as synonyms.
Example 5.2 Simple synonym definition
<synonym-set> <seq><w>photo</w></seq> <seq><w>photograph</w></seq> <seq><w>pic</w></seq> <seq><w>picture</w></seq> </synonym-set>
Example 5.3 shows an example label dictionary entry that causes Lingo3G to promote the phrase web search in the clustering results.
Example 5.3 Simple label dictionary entry
<entry weight="2.0"> <seq match="eltm"><w>web</w><w>search</w></seq> </entry>
A common component to synonym and label dictionary specifications is a label matching pattern, which Lingo3G uses to decide if a cluster label should be processed with the use of a lexical resource or not. Lingo3G supports several types of label matching rukes: word-, regular expression and surface label image based patterns. They are described in detail in the following sections.
Word-based patterns, represented in the lexical resource XML files by
<seq> elements, are based around matching whole
words of the pattern against whole
words comprising a label. A label matching pattern can
consist of elements of three types: words, represented by <w>
elements, numeric tokens, represented by <n> elements (see
the section called “Numeric token matching”), and part of speech tags
(see section Section 5.4.2).
Important
Word-based matching is both case- and inflection-insensitive, which means that a single word cluster specified in the pattern will match all variants of the word irrespective of their case (Cluster or CLUster) and grammatical form (clustering, clustered or clusters).
Additionally, word-based matches can be restricted to a combination
of four positions within the cluster label: exact, leading, trailing
and middle. Matching position restrictions can be applied to a
pattern using the match attribute of the
<seq> element. The value of the match
attribute can be any combination of letters e
(exact), l (leading), t
(trailing) and m (middle).
Exact single word matching is the simplest and fastest label
matching pattern offered by Lingo3G. It is defined by exactly one
<w> element containing the word to be
matched.
The pattern shown in Example 5.4 will match one-word labels consisting of the word the, e.g. the, THE or The.
Because single word matching is also inflection-insensitive, the pattern shown in Example 5.5 will match labels containing any grammatical variant of the word cluster, e.g. clustering, clustered or cluster.
Note
Please note that when the match attribute of the
<seq> element is not specified or has a
value of e, exact matching will be assumed.
This kind of pattern will match only one-word labels. To match labels beginning,
ending or containing a single word, you need to explicitly specify
the appropriate matching position as shown in the following
sections.
To match labels beginning in a
word, add to the <seq> element a match attribute with a value
containing the letter l (leading). The pattern shown in
Example 5.6 will match
labels that consist of two or more words and begin in the word
for, e.g. for you or
for web search
Note
Please note that single word leading patterns will not match one-word labels. To make a pattern
match both one-word labels and labels beginning in the specified
word, set the match attribute of the <seq> element to
el.
To match labels ending in a word,
add to the <seq> element a match attribute with a value containing
the letter t (trailing). The pattern shown in Example 5.7 will match labels
that consist of two or more words and end in the word
about, e.g. information
about or more web sites about
Note
Please note that single word trailing patterns will not match one-word labels. To make a pattern
match both one-word labels and labels ending in the specified word,
set the match attribute of the <seq> element to
et.
To match words contained somewhere in the
middle of a label, add to the <seq> element a match
attribute with a value containing the letter m (middle).
The pattern shown in Example 5.8 will match labels
that consist of three or more words and contain in the word
eye at one of the middle positions, e.g.
for your eyes only or bird's eye
view.
Note
Please note that single word middle patterns will match neither
one- nor two-word labels. To make a pattern match a word
anywhere in the label (including one-word labels), set the match
attribute of the <seq> element to eltm.
In many cases it might be useful to combine certain matching
position restrictions in one rule. This can be done by specifying
more than one letter in the match attribute of the <seq> element,
which will translate to an or condition between
the corresponding position restrictions.
Example 5.9 shows a pattern useful for matching labels consisting of, beginning or ending in the of function word, e.g. of, of Poland or President of. Please note that the pattern will not match labels containing the word of somewhere in the middle, e.g. President of Poland.
Example 5.10 shows a pattern that can be used to match labels containing the word politics anywhere in the label, including one-word labels consisting only of that word, e.g. about politics, political news, all politically correct or politic
A word sequence exact matching pattern is defined by a <seq> tag
containing more than one <w> element, each
of which represents one word of the word sequence to be matched.
The pattern shown in Example 5.11 will match two-word labels consisting of any grammatical variant of the phrase document clustering, e.g. documented clusters, documents clustered or document clustering.
Note
Please note that when the match attribute of the
<seq> element is not specified or has a
value of e, exact matching will be assumed.
Such patterns will match only labels that consist of exactly the
same number of words as the matching pattern does. To match labels
beginning in, ending in or containing a sequence of words, you need to
explicitly specify the appropriate matching position as shown in
the following sections.
To match labels beginning in a
sequence of words, add to the <seq> element a match attribute with
a value containing the letter l (leading). The pattern
shown in Example 5.12
will match labels that consist of three or more words and begin in
the information about phrase, e.g.
information about clustering or
information about web services.
Example 5.12 Word sequence leading matching pattern
<seq match="l"> <w>information</w><w>about</w> </seq>
Note
Please note that word sequence leading patterns will match only labels consisting of more words than the matching pattern.
To match labels ending in a
sequence of words, add to the <seq> element a match attribute with
a value containing the letter t (trailing). The pattern
shown in Example 5.13
will match labels that consist of four or more words and begin in
the professional consulting services phrase, e.g.
data mining professional consulting services or
Java professional consulting service.
Example 5.13 Word sequence leading matching pattern
<seq match="t"> <w>professional</w><w>consulting</w><w>services</w> </seq>
Note
Please note that word sequence trailing patterns will match only labels consisting of more words than the matching pattern.
To match word sequences contained somewhere in the middle of a label, add to the <seq>
element a match attribute with a value containing the letter
m (middle). The pattern shown in Example 5.14 will match labels
that consist of four or more words and contain in the phrase
hot offer at one of the middle positions, e.g.
check hot offers now or don't miss
hot offers anymore.
Note
Please note that word sequence middle patterns will match
only labels containing at least two more words than the
pattern does. To make a pattern match a word sequence
anywhere in the label (including exact matches), set the
match attribute of the <seq> element to eltm.
To combine a number of matching positions in one rule, specify more
than one letter in the match attribute of the <seq> element, which
will translate to an or condition between the
corresponding position restrictions.
Example 5.15 shows a pattern that can be used to match labels containing the phrase best deals anywhere in the label, including one-word labels consisting only of that phrase, e.g. check our best deals, best deals wait for you, browse best deals here or best deal.
The word-based patterns can also include an <n> element for
matching numeric tokens (e.g. 2007,
'07, -20,
$50, 24/12/2006,
12,5, 15,7,
100%, 2nd,
5pm).
Example 5.16 shows a pattern that can be used to match labels containing the phrase Page X of Y, where X and Y are any numbers.
If part of speech information is available, either from a word dictionary (see Section 5.3) or from an external linguistic engine, it can be used while cluster label matching. The following XML elements are available:
-
<fnc>— matches a function word, e.g. have or about -
<verb>— matches a verb, e.g. goes -
<noun>— matches a noun, e.g website -
<adj>— matches an adjective, e.g. cool -
<adv>— matches an adverb, e.g. fully -
<geo>— matches a geographical term, e.g. London -
<name>— matches a proper noun, e.g. John
The first rule shown in Example 5.17 matches labels being, beginning or ending in a function word, e.g with, for John or information about, while the second one — labels being or ending in adjectives, e.g. spectacular or London famous.
Example 5.17 Part of speech-based token matching patterns
<seq match="lte"> <fnc /> </seq> <seq match="et"> <adj /> </seq>
Important
In order for part of speech-based label filtering to work correctly, part of speech information must be defined in a corresponding word dictionary (see Section 5.3) or an external linguistic engine must be integrated with Lingo3G. In case both sources of part of speech information are available, Lingo3G will assume a union of part of speech flags provided by the individual sources.
Surface image label matching rules are similar to word-based matching and they are also expressed using similar syntax. The difference is that the pattern is matched literally to the final surface form of a label, not its stem-based token stream. So a label rule expressed as:
<seq>car</seq>
will only match the surface label car, not cars. Compare this to the word-based definition:
<seq><w>car</w></seq>
which will match any word stemming to the same lemma as car does.
The presence or absence of <w> tag makes a difference and determines the type of the
rule.
Like with
word-based matching rules, surface rules have a match attribute to express
the type of matching that triggers the rule (leading, trailing, exact match). The m (middle)
match type effectively becomes a substring match for surface forms. Consider the following example:
Example 5.18 Surface matching rules
<entry><seq>foobar</seq></entry> <entry><seq match="l">foo</seq></entry> <entry><seq match="t">bar</seq></entry> <entry><seq match="m">abc</seq></entry>
This definition will match an exact label foobar (first rule;
default match type is e; exact), any label starting with foo,
any label ending in bar and any label that constains a substring
abc.
Important
While it may be tempting to use surface rules to express all kinds of unwanted labels, there is an inherent performance penalty associated with surface rules that is not present when word-based matching rules are used instead. For languages where word demarcation is clear (as in English), it is highly recommended to use explicit word-based patterns. Surface rules are most useful for languages where the tokenization of the label is not straightforward (Japanese, Chinese).
Regular expression-based patterns, represented in the lexical
resource XML files by <exp> elements, are based around matching a regular expression against a label as a
whole. A label is considered as matching a regexp if the
regular expression matches any
portion of the label.
Similarly to word-based patterns, regexp-based patterns are case-insensitive. However, because regexp matching is done against labels in their literal form (i.e. including spaces between words), regexp-based patterns are inflection-sensitive. For the same reason, matching position restrictions are not applicable in the regexp-based patterns – they can be easily implemented using appropriate regexp constructs. For a specification of the regular expression syntax used by Lingo3G, please refer to the Pattern class in Java 2 API Specification.
Important
Regular expression-based label matching is a powerful mechanism, but it can also result in a dramatic decrease of clustering performance. Therefore, it should be used only when a similar effect cannot be achieved by a finite number of word-based label matching patterns.
The pattern shown in Example 5.19 will match any label containing the car+ot\d? regular expression, e.g. Carrot5, carrrrot juice or eating carrots is good for your health.
To restrict the position at which the regexp pattern is matched
within the label, you can use such regexp constructs as:
^ (the beginning of a line) and
$ (the end of a line). The pattern shown in Example 5.20 will match only labels starting
with the expression car+ot\d?, e.g.
Carrot5 or Carrot5
Website.
Example 5.21 shows a pattern that will match one-word labels that exactly contain the car+ot\d? expression, e.g. Carrot5 or carrrrrot.
To ensure that a regexp matches labels containing a certain number of
words, you can use the \b (word boundary) or \s
(whitespace) constructs. Pattern shown in Example 5.22 will match labels having at
least two words and starting with the car+ot\d?
expression, e.g. Carrot5 Test or
carrot juice. However, this expression will
not match the label
Carrot5.
Example 5.23 shows a pattern that will match any label that contains a time-span definition similar to 9am to 5pm, e.g. working from 10am to 9pm today. Please note that this pattern will not match the label working 9am to 5pm.
Tip
Lingo3G ensures that words of labels fed to the regexp matching engine are always separated by one space character (unless clustering a document is Chinese, in which case no spaces are inserted into labels), so Example 5.23 can be written as:
<exp> \d{1,2}am to \d{1,2}pm </exp>
Tip
To avoid XML syntax problems, some regular expressions may need a CDATA section, e.g.:
<exp><![CDATA[<xmltag/>]]></exp>
Using the label dictionary, you can influence the way Lingo3G chooses labels to describe clusters. You can prevent Lingo3G from choosing certain words or phrases (e.g. stop words or abusive language) as cluster labels, and at the same time promote others (e.g. product or brand names).
Label dictionaries are specified in XML files named according to the following pattern:
label-dictionary.language-code.xml,
where language-code is the
ISO-639 code of the language for which this dictionary should be used,
e.g. en for English. A sample label dictionary
file is shown in Example 5.24.
Example 5.24 A sample label dictionary file
<?xml version="1.0" encoding="UTF-8"?>
<label-dictionary>
<include base-name="domain-specific-labels" />
<!-- Remove all function words defined by the word-dictionary -->
<entry>
<seq match="elt"><fnc /></seq>
</entry>
<entry>
<seq match="eltm"><w>banned</w></seq>
</entry>
<entry>
<exp>\d{1,2}(am|pm)</exp>
</entry>
<entry weight="2.0>
<seq match="eltm"><w>orange</w></seq>
</entry>
<entry weight="2.0>
<seq match="eltm">
<w>clustering</w><w>engine</w>
</seq>
</entry>
<!--
... more entries here
-->
</label-dictionary>
Each <entry> element must contain exactly one label matching pattern
(see Section 5.4), which determines the
labels influenced by that entry. If an <entry> element does not contain
the weight attribute or the value of that attribute is less or equal
to 0.0, all labels matching the entry's pattern will be excluded from
processing and will not appear in the final results. Entries with
weight values in the range from 0.0 to 1.0 will decrease the label's
chances of appearing in the results – the closer the weight
value to 0.0, the lower the probability of choosing the matching as a
cluster label. Entries with weight values greater than 1.0 will
encourage Lingo3G to use the matching labels while describing clusters
– the larger the weight, the more likely the matching label
will be to appear in the results. Finally, weight values of 1.0 do
not affect the label selection process, and therefore entries the
weight value will be omitted.
The label dictionary file shown in Example 5.24 will cause Lingo3G to remove labels containing any form of the word banned, beginning, ending or equal to the and matching a regular expression pattern describing the time of the day. It will also promote labels containing any form of the word orange or the phrase clustering engine.
Note
If a label matches two dictionary entries, one with weight equal to 0.0 and the other one with weight greater than 0.0, Lingo3G will give priority to the the entry with weight equal to 0.0 and disregard the other entry. Moreover, for performance reasons, if a label matches more than one dictionary entry of the same priority, Lingo3G will arbitrarily choose and apply one of the matching entries.Tip
You can split a large label dictionary into smaller parts using the
include tag, see Section 5.7.
Using synonyms, you can tell Lingo3G that certain sets of words or phrases (e.g. photo, photograph, pic and picture) have the same meaning and should be treated as synonymous during clustering.
Synonyms are specified in XML files located in the
resources/ directory and complying with the
following naming pattern:
synonyms.language-code.xml,
where language-code is the
ISO-639 code of the language for which this dictionary should be used,
e.g. en for English. A sample synonyms file is
shown in Example 5.25.
Example 5.25 A sample synonyms file
<?xml version="1.0" encoding="UTF-8"?>
<synonym-sets>
<synonym-set>
<seq><w>nyc</w></seq>
<seq><w>new</w><w>york</w><w>city</w></seq>
</synonym-set>
<synonym-set label="Data Mining!">
<seq><w>dm</w></seq>
<seq><w>data-mining</w></seq>
<seq><w>data</w><w>mining</w></seq>
</synonym-set>
<!--
... more synonym sets here
-->
</synonym-sets>
Each <synonym-set> element can contain any number of label matching patterns
(see Section 5.4), which define the set
of labels that Lingo3G should treat as synonymous. Additionally, an
arbitrary label to be displayed instead of the synonym can be specified
using the label attribute.
Note
Synonyms do not apply while processing the label dictionary (see Section 5.5). Therefore, if a dictionary entry matches a label that has synonyms, the synonymous labels will not be affected by that entry. If the synonymous labels are to be affected, they need dedicated entries in the label dictionary.
Note
Note: For performance reasons, the synonym processing engine does not support transitive definitions. For example, the following two declarations will not be logically collapsed into one:
<synonym-set> <seq><w>dm</w></seq> <seq><w>data</w><w>mining</w></seq> </synonym-set> <synonym-set> <seq><w>dm</w></seq> <seq><w>data-mining</w></seq> </synonym-set>
Therefore, please put transitively equivalent synonyms into one <synonym-set>
element, e.g.:
<synonym-set> <seq><w>dm</w></seq> <seq><w>data-mining</w></seq> <seq><w>data</w><w>mining</w></seq> </synonym-set>
Tip
You can split a large synonym dictionary into smaller parts using the
include tag, see Section 5.7.
To better manage your dictionaries, you may want to split them into several files
and use the <include> tag to import the partial dictionaries
into the main dictionary file.
There are several use cases in which the <include> tag can turn out useful:
-
Language-independent entries All language-specific label dictionaries include a common file called
label-dictionary.common.xml. The common file contains a number of default part-of-speech based entries, such as removing labels being, starting or ending in a function word, that are applicable in all languages. -
Common stop words for multilingual clustering All language-specific word dictionaries include a common file called
word-dictionary.common.xml. The common file contains the most popular stop words in English, Spanish and German and its aim is to prevent meaningless labels in case of multilingual documents. -
Domain-specific dictionaries If you maintain several domain-specific dictionaries, you may want to put the dictionary for each in its own XML file.
The <include> tag can be used in all Lingo3G dictionaries, i.e.
label, word and synonym dictionary. The file to be included is specified by
one of the following attributes of the <include> tag:
-
nameFull name of the dictionary file to include, including the language code and the.xmlextension, e.g.word-dictionary.common.xml. -
base-nameBase name of the dictionary file to include, to which Lingo3G will automatically append the language code of the parent dictionary and the.xmlextension. For example, anincludetag with the base name ofword-dictionary-customoccurring in theword-dictionary.en.xmldictionary will cause Lingo3G to include the contents of theword-dictionary-custom.en.xmlfile.
Note
If the including and included file contain an entry referring to the same word, sequence of words or tags, the entry from the entry from the included file overrides the entry found in the including file.
This chapter discusses a number of typical fine-tuning scenarios for the Lingo3G clustering algorithm.
The quality of clusters and their labels largely depends on the characteristics of documents provided on the input. Although there is no general rule for optimum document content, below are some tips worth considering.
-
Lingo3G is designed for small or medium collections of documents. The most important characteristic of Lingo3G to keep in mind is that it performs in-memory clustering. For this reason, as a rule of thumb, Lingo3G should successfully deal with up to a few tens of thousands of documents, ideally a few paragraphs each.
-
Provide a minimum of 20 documents. Lingo3G will work best with a set of documents similar to what is normally returned by a typical search engine. While about 20 is the minimum number of documents you can reasonably cluster, the optimum would fall in the 100 – 500 range.
-
Provide contextual snippets if possible. If the input documents are a result of some search query, provide contextual snippets related to that query, similar to what web search engines return, instead of full document content. Not only will this speed up processing, but also should help the clustering algorithm to cover the full spectrum of topics dealt with in the search results.
-
Minimize "noise" in the input documents. All kinds of "noise" in the documents, such as truncated sentences (sometimes resulting from contextual snippet extraction suggested above) or random alphanumerical strings may decrease the quality of cluster labels. If you have access to e.g. a few sentences' abstract of each document, it is worth checking the quality of clustering based on those abstracts. If you can combine this with the previous tip, i.e. extract complete sentences matching user's query, this should improve the clusters even further.
Let us once again stress that there are no definite generic guidelines for the best content for clustering, it is always worth experimenting with different combinations. Please contact Carrot Search for advice for a specific application.
The best tool for experimenting and tuning Lingo3G clustering is the Lingo3G Document Clustering Workbench. Figure 6.1 shows the main components involved in the tuning process.
Figure 6.1 Tuning clustering in Lingo3G Document Clustering Workbench

|
|
The results editor presents documents and clusters. Changes made in the Attributes view will affect the currently active results editor. |
|
|
The Attributes view, where you can see and change values of clustering algorithm's attributes. |
|
|
The Attribute Info view, which shows documentation for specific attributes. Hold the mouse pointer over an attribute's label to see its documentation. |



Opening the Attributes view. By default, the Attributes view shows on the right hand side of the Lingo3G Document Clustering Workbench. You can open the view at any time by choosing Window > Show view > Attributes.
Setting modified attributes as default for new queries. If you modified a number of attributes for an algorithm and would like to use the modified values for new queries, choose the Set as defaults for new queries from the Attributes view's context menu (Figure 6.2).

Restoring default attribute values. To reset the attributes to their default values, choose the Reset to defaults option from the Attributes view's context menu (Figure 6.2). To bring the attributes back to their factory defaults, choose the Reset to factory defaults option.
Loading and saving attribute values to XML.
To load or save attribute values to an XML file, use the Open
and Save as... options available under the
![]() icon on the Attributes view's menu bar.
icon on the Attributes view's menu bar.
Accessing attribute documentation. To see the documentation for a specific attribute, hold the mouse pointer over the attribute's label and its documentation will show in the Attribute Info view.
Please see Chapter 5 for complete information about the lexical resource files (word and label dictionaries, synonyms) which allow to fine-tune the cluster labels produced by Lingo3G
The Other Topics cluster contains documents that do not belong to any other cluster generated by the algorithm. Depending on the input documents, the size of this cluster may vary from a few to tens of documents.
By tuning parameters of the clustering algorithm, you can reduce the number of unclustered documents, though bringing the number down to 0 is unachievable in most cases. Please note that minimizing the Other Topics cluster size is usually achieved by forcing the algorithm to create more clusters, which may degrade the perceived clustering quality.
To reduce the size of the Other Topics cluster generated by Lingo3G:
-
Reset attribute values to factory defaults.
-
Increase the Maximum top-level clustering passes above the default value or set it to zero to force Lingo3G to create as many clusters as possible.
-
Increase the Document coverage target above the default value.
-
Increase the Single word label weight above the default value. Note that this will increase the number of one-word labels, which may not always be desirable.
Tip
When clustering more than 100 documents, further reductions in the size of Other Topics can be achieved by lowering Word DF cut-off scaling and Phrase DF cut-off scaling. This will force Lingo3G to consider lower-frequency words and phrases when clustering and hence creating more clusters. Please note that lowering the values will significantly increase the clustering time.
Tip
To apply the changes to Lingo3G applications, please follow instructions from Chapter 7.
To make the clusters more general (containing more documents, covering broader topics):
-
Reset attribute values to factory defaults.
-
Increase the Single word label weight above the default value, possibly up to 1.00. Note that this will increase the number of one-word labels, which may not always be desirable.
-
Increase the Maximum cluster size above the default value, possibly up to 1.00.
-
Increase the Minimum cluster size in steps of 0.01 to eliminate the clusters with smallest numbers of documents.
-
To further increase the size of clusters, try lowering the Merge threshold. This will cause Lingo3G do merge similar clusters.
Tip
To apply the changes to Lingo3G applications, please follow instructions from Chapter 7.
To make the clusters more specific (containing fewer documents, covering more narrow topics):
-
Reset attribute values to factory defaults.
-
Decrease the Maximum cluster size below the default value to eliminate large clusters.
-
Decrease the Maximum top-level clustering passes to 0 to force Lingo3G to create as many clusters as possible.
-
If there are too many one-word meaningless cluster labels, try lowering the Single word label weight. Setting this attribute to 0.00 will elminate one-word labels alltogether.
Tip
To apply the changes to Lingo3G applications, please follow instructions from Chapter 7.
You can use the Lingo3G Document Clustering Workbench to run simple performance benchmarks of Lingo3G. The benchmarks repeatedly cluster the content of the currently opened editor and report the average clustering time. You can use the benchmarking results to measure the impact of different algorithm's attribute settings on its performance and estimate the the maximum number of clustering requests that the algorithm can process per second.
To perform a performance benchmark:
- In the Search view, choose the algorithm to benchmark and perform the query to be used for benchmarking.
-
Open the Benchmark view.
- Press to start the benchmark. After the benchmark completes, you should see the measured clustering time average, standard deviation, minimum and maximum.

Tip
To asses the performance impact of different attribute settings on one algorithm, you can open two or more editors with the same results clustered by the algorithm, set different attribute values in each editor and run benchmarking for each editor separately. The benchmark view remembers the last result for each editor, so you can compare the performance figures by simply switching between the editors.
Tip
By default, the benchmarking view uses only a single processing unit on multi-processor or multi-core machines. You can increase the number of benchmark threads in the Threads section.
Caution
Benchmark results may vary and be different from the results acquired on production machines due to other programs running in the background, operating system, hardware-specific considerations and even different Java Virtual Machine settings. Always fine-tune your clustering setup in the target deployment environment.
This chapter will show you how to add new document sources and tune clustering in Lingo3G applications.
Key concepts in customizing and tuning Lingo3G applications are component suites and component attributes described in the following sections.
Component suite is a set of Carrot2 components, such as document sources or clustering algorithms, configured to work within a specific Lingo3G application. For each component, the component suite defines the component's identifier, label, description and also a number of component- and application-specific properties, such as the list of example queries.
Component suites are defined in XML files read from application-specific locations described in further sections of this chapter. An example component suite definition is shown in Figure 7.1.
Figure 7.1 Example Carrot2 component suite
<component-suite>
<sources>
<source id="lucene"
component-class="org.carrot2.source.lucene.LuceneDocumentSource"
attribute-sets-resource="lucene.attributes.xml">
<label>Lucene</label>
<title>Apache Lucene</title>
<mnemonic>L</mnemonic>
<description>
Apache Lucene index (local index access).
</description>
<icon-path>icons/lucene.png</icon-path>
<example-queries>
<example-query>data mining</example-query>
<example-query>london</example-query>
<example-query>clustering</example-query>
</example-queries>
</source>
</sources>
<algorithms>
<algorithm id="lingo3g"
component-class="com.carrotsearch.lingo3g.Lingo3GClusteringAlgorithm"
attribute-sets-resource="lingo3g.attributes.xml">
<label>Lingo3G</label>
<title>Lingo3G Clustering</title>
</algorithm>
</algorithms>
<include suite="source-bing.xml" />
</component-suite>
The component suite definition can consist of the following elements:
-
sourcesDocument source definitions, optional. -
algorithmsClustering algorithm definitions, optional. -
includeIncludes other XML component suite definitions, optional. The resource specified in thesuiteattribute will be loaded from the current thread's context class loader.
Common parts of the source and algorithm tags include:
-
idIdentifier of the component within the suite, required. Identifiers must be unique within the component suite scope. -
component-classFully qualified name of the processing component class, required. -
attribute-sets-resourceXML file to load the component's attributes from. The resource specified in this attribute will be loaded from the current thread's context class loader. For the syntax of the XML file, please see Section 7.1.2. -
labelA human readable label of the component, required. -
labelA human readable title of the component, required. The title will be usually slightly longer than the label. -
descriptionA longer description of the component, optional. -
icon-pathApplication specific definition of the component's icon.
Additionally, for the source tag you can use the example-queries tag
to specify some example queries the applications may show for this source.
Component attribute is a specific property of a Carrot2 component that influences its behavior, e.g. the number of search results fetched by a document source or the depth of cluster hierarchy produced by a clustering algorithm. Each attribute is identified by a unique string key, Chapter 9 lists and describes all available components and their attributes.
You can specify attribute values for specific components in the component suite
using attribute sets. Attribute sets are defined in XML files
referenced by the attribute-sets-resource attribute of the component's
entry in the component suite. Figure 7.2
shows an example attribute set definition.
Figure 7.2 Example Carrot2 attribute set
<attribute-sets>
<attribute-set id="lucene">
<value-set>
<label>Lucene</label>
<attribute key="LuceneDocumentSource.directory">
<value>
<wrapper class="org.carrot2.source.lucene.FSDirectoryWrapper">
<indexPath>/path/to/lucene/index/directory</indexPath>
</wrapper>
</value>
</attribute>
<attribute key="org.carrot2.source.lucene.SimpleFieldMapper.contentField">
<value type="java.lang.String" value="summary" />
</attribute>
<attribute key="org.carrot2.source.lucene.SimpleFieldMapper.titleField">
<value type="java.lang.String" value="title" />
</attribute>
<attribute key="org.carrot2.source.lucene.SimpleFieldMapper.urlField">
<value type="java.lang.String" value="url" />
</attribute>
</value-set>
</attribute-set>
</attribute-sets>
An attribute-sets element can contain one or more
attribute-sets. Each attribute-set must specify a unique
id and a value-set.
Saving attributes to XML using Lingo3G Document Clustering Workbench
As the syntax of the value elements depends on the type of the
attribute being set, the easiest way to obtain the XML file is to use
the Lingo3G Document Clustering Workbench.
To generate attribute set XML for a document source:
-
In the Search view, choose the document source for which you would like to save attributes.
-
Use the Search view to set the desired attribute values.
-
Choose the Save as... option from Search view's menu bar. Lingo3G Document Clustering Workbench will suggest the XML file name based on the value of the document source's
attribute-sets-resourceattribute.
Note
Please note that the Lingo3G Document Clustering Workbench will remove a number of common attributes from the XML file being saved, including: query, start result index, number of results.
To generate attribute set XML for a clustering algorithm:
-
In the Search view, choose the clustering algorithm for which you would like to save attributes. Choose any document source and perform processing using the selected algorithm.
-
Use the Attributes view to set the desired attribute values.
-
Choose the Save as... option from Attribute view's menu bar. Lingo3G Document Clustering Workbench will suggest the XML file name based on the value of the clustering algorithm's
attribute-sets-resourceattribute.
To add a document source tab to the Lingo3G Document Clustering Server:
-
Open for editing the
suite-dcs.xmlfile, located in theWEB-INF/suitesdirectory of the DCS WAR file located in thewar/of the DCS distribution. -
Add a descriptor for the document source you want to add to the
sourcessection of thesuite-dcs.xmlfile. Alternatively, you may want to use theincludeelement to reference one of the example document source descriptors shipped with the application (e.g.source-lucene.xml). Please see Section 7.1.1 for more information about the component suite XML file. -
If the document source you are adding requires setting specific attribute values (e.g. index location for the Lucene document source), use the Lingo3G Document Clustering Workbench to generate the attribute set XML file. Place the generated XML file in
WEB-INF/suitesand make sure it is appropriately referenced by theattribute-sets-resourceattribute of the descriptor added in the previous step. -
Restart the DCS. The new document source should be available for processing.
To run the Lingo3G Document Clustering Server with custom attributes of the Lingo3G clustering algorithm:
-
Use the Lingo3G Document Clustering Workbench to save the attribute set XML file with the desired Lingo3G attribute values.
-
Replace the contents of
algorithm-lingo3g-attributes.xml, located in theWEB-INF/suitesdirectory of the DCS WAR file, located in thewar/directory of the DCS distribution, with the XML file saved in the previous step. -
Restart the DCS.
To run the Lingo3G Command Line Interface with custom attributes of the Lingo3G clustering algorithm:
-
Use the Lingo3G Document Clustering Workbench to save the attribute set XML file with the desired Lingo3G attribute values.
-
Replace the contents of
algorithm-lingo3g-attributes.xml, located in the/suitesdirectory of the CLI distribution, with the XML file saved in the previous step. -
Run the CLI application.
The Java API distribution package contains examples showing how to customize
attributes of the clustering algorithms. Please see the
com.carrotsearch.lingo3g.examples.clustering.UsingAttributes class or
the JavaDoc overview page.
This chapter discusses solutions to some common problems with Lingo3G code or applications.
To increase Java heap size for Lingo3G Document Clustering Workbench, use the following command line parameters:
lingo3g-workbench -vmargs -Xmx256m
Tip
Using the above pattern you can specify any other JVM options if needed.
Tip
You can also add JVM path and options to the eclipse.ini
file located in in Lingo3G Document Clustering Workbench installation directory. Please see
Eclipse Wiki
for a list of all available options.
To get the stack trace (useful for Lingo3G team to spot errors) corresponding to a processing error in Lingo3G Document Clustering Workbench, follow the following procedure:
-
Click OK on the Problem Occurred dialog box (Figure 8.1).
-
Go to Window > Show view > Other... and choose Error Log (Figure 8.2).
-
In the Error Log view double click the line corresponding to the error (Figure 8.3).
-
Copy the exception stack trace from the Event Details dialog and pass to Lingo3G team (Figure 8.4).




If you see question marks ("?") instead of Chinese, Polish or other special Unicode characters in clusters and documents output by the Lingo3G Web Application
The Lingo3G Web Application running under a Web application container (such as Tomcat) relies on proper decoding of Unicode characters from the request URI. This decoding is done by the container and must be properly configured at the container level. Unfortunately, this configuration is not part of the J2EE standard and is therefore different for each container.
For Apache Tomcat, you can enforce the URI decoding code page at the connector
configuration level. Locate server.xml file inside
Tomcat's conf folder and add the following attribute to
the Connector section:
URIEncoding="UTF-8"
A typical connector configuration should look like this:
<Connector port="8080" maxThreads="25"
minSpareThreads="5" maxSpareThreads="10"
minProcessors="5" maxProcessors="25"
enableLookups="false" redirectPort="8443"
acceptCount="10" debug="0"
connectionTimeout="20000" URIEncoding="UTF-8" />
This section lists and describes all attributes of all Lingo3G clustering algorithm. Please see Chapter 7 for information on how you can set component attributes in different Lingo3G applications.
- Accent folding
- Allow one-document clusters
- Capitalize non function word
- Dashed words label filter
- Dashed words synonyms enabled
- Default clustering language
- Dictionary label filter
- Dictionary synonyms enabled
- Flat merging
- Hierarchical merging
- Language aggregation strategy
- Language recognition
- Lowercase function words
- Maximum hierarchy depth
- Maximum label length
- Maximum sub-level clustering passes
- Maximum tokens per document
- Maximum word document frequency
- Merge threshold
- Minimum cluster size for subclusters
- Minimum label length
- Minimum length label filter
- Normalize input for language recognition
- Number-only label filter
- One letter word label filter
- Precise document assignment slop multiplier
- Precise document assignment slop offset
- Preferred label length deviation
- Preferred label length
- Put promoted labels at hierarchy root
- Remove repeated synonyms from labels
- Repeated words label filter
- Trailing genitive label filter
- Aggressive cluster cloning control
- Allow sub-phrase cluster labels (Japanese only)
- Built-in database for label filtering
- Built-in database for stemming
- Capitalized word label scorer weight
- Cluster cloning control
- Cluster-document overlap label scorer weight
- Cluster scoring fields
- Combined cluster score balance
- Content fields
- Dictionary weight scorer weight
- Document count label scorer weight
- Grammatical variant label scorer weight
- Hierarchical merging with labels
- Label dictionary
- Label override threshold
- Label token delimiter
- Left complete label filter
- License resource
- Maximum improvement iterations
- Max key phrases per document (Japanese only)
- Minimum language confidence
- Neighborhood size
- Normalize scores
- Phrase DF cut-off scaling
- Query word label scorer weight
- Query word label weight
- Resource lookup facade
- Right complete label filter
- Stemmer factory
- Synonym dictionary
- TF/DF ratio label scorer weight
- TF label scorer weight
- Title fields
- Title word label scorer weight
- Tokenizer factory
- Unindexed word label scorer weight
- Unknown word handling
- Word count label scorer weight
- Word DF cut-off scaling
- Word dictionary
- Accent folding
- Aggressive cluster cloning control
- Allow numbers in labels
- Allow one-document clusters
- Allow sub-phrase cluster labels (Japanese only)
- Built-in database for label filtering
- Built-in database for stemming
- Capitalized word label scorer weight
- Capitalize non function word
- Cluster cloning control
- Cluster count base
- Cluster-document overlap label scorer weight
- Cluster scoring fields
- Clusters
- Combined cluster score balance
- Content fields
- Dashed words label filter
- Dashed words synonyms enabled
- Default clustering language
- Dictionary label filter
- Dictionary synonyms enabled
- Dictionary weight scorer weight
- Document count label scorer weight
- Document coverage target
- Documents
- Flat merging
- Grammatical variant label scorer weight
- Hierarchical merging
- Hierarchical merging with labels
- Label dictionary
- Label override threshold
- Label token delimiter
- Language aggregation strategy
- Language recognition
- Left complete label filter
- License resource
- Lowercase function words
- Maximum cluster size
- Maximum hierarchy depth
- Maximum improvement iterations
- Maximum label length
- Maximum sub-level clustering passes
- Maximum tokens per document
- Maximum top-level clustering passes
- Maximum word document frequency
- Max key phrases per document (Japanese only)
- Merge threshold
- Minimum cluster size
- Minimum cluster size for subclusters
- Minimum label length
- Minimum language confidence
- Minimum length label filter
- Neighborhood size
- Normalize input for language recognition
- Normalize scores
- Number-only label filter
- One letter word label filter
- Phrase DF cut-off scaling
- Precise document assignment slop multiplier
- Precise document assignment slop offset
- Precise document assignment
- Preferred label length deviation
- Preferred label length
- Put promoted labels at hierarchy root
- Query
- Query word label scorer weight
- Query word label weight
- Reload resources
- Remove repeated synonyms from labels
- Repeated words label filter
- Resource lookup facade
- Right complete label filter
- Single word label weight
- Stemmer factory
- Synonym dictionary
- TF/DF ratio label scorer weight
- TF label scorer weight
- Title fields
- Title word label scorer weight
- Tokenizer factory
- Trailing genitive label filter
- Unindexed word label scorer weight
- Unknown word handling
- Word count label scorer weight
- Word DF cut-off scaling
- Word dictionary
| Key |
allow-one-document-clusters
|
| Direction |
Input
|
| Level |
MEDIUM
|
| Description | When enabled, the algorithm will not prune clusters containing only one document.
Tip: For collections larger than 100 documents, to get one-document clusters, you also need to set
Tip: When one-document clusters are allowed, the number of larger clusters may decrease. To obtain more larger clusters while keeping the one-document ones, increase Performance impact: medium. |
| Required |
no
|
| Scope | Processing time |
| Value type |
java.lang.Boolean
|
| Default value |
false
|
| Attribute builder |
Lingo3GAttributesDescriptor.AttributeBuilder#allowOneDocumentClusters()
|
| Key |
combined-cluster-score-balance
|
| Direction |
Input
|
| Level |
ADVANCED
|
| Description | Decides whether document count or cluster label score should have larger impact on the cluster score.
Setting this parameter to 0.5 will cause the clustering engine to assign equal weight to document count and cluster label score during cluster score calculation. A value equal to 1.0 will cause the clustering engine to use only document count for cluster scoring. Similarly, with the 0.0 value, only the cluster label score will be used. Performance impact: none |
| Required |
no
|
| Scope | Processing time |
| Value type |
java.lang.Double
|
| Default value |
0.5
|
| Min value |
0.0
|
| Max value |
1.0
|
| Attribute builder |
Lingo3GAttributesDescriptor.AttributeBuilder#combinedClusterScoreBalance()
|
| Key |
max-cluster-size
|
| Direction |
Input
|
| Level |
BASIC
|
| Description | Determines the maximum allowed size of a cluster in relation to the parent cluster size.
E.g. a value of 0.4 means that clusters must not contain more than 40% of the parent cluster's documents (of all documents in case of top-level clusters). This parameter is meaningful only if 'Document count label scorer weight' is greater than 0. Performance impact: none |
| Required |
no
|
| Scope | Processing time |
| Value type |
java.lang.Double
|
| Default value |
0.4
|
| Min value |
0.0
|
| Max value |
1.0
|
| Attribute builder |
Lingo3GAttributesDescriptor.AttributeBuilder#maxClusterSize()
|
| Key |
min-cluster-size
|
| Direction |
Input
|
| Level |
BASIC
|
| Description | Determines the minimum allowed size of a cluster in relation to the parent cluster size.
E.g. a value of 0.4 means that clusters must not contain less than 40% of the parent cluster's documents (of all documents in case of top-level clusters). This parameter is meaningful only if 'Document count label scorer weight' is greater than 0. Performance impact: none |
| Required |
no
|
| Scope | Processing time |
| Value type |
java.lang.Double
|
| Default value |
0.0
|
| Min value |
0.0
|
| Max value |
1.0
|
| Attribute builder |
Lingo3GAttributesDescriptor.AttributeBuilder#minClusterSize()
|
| Key |
min-cluster-size-for-subclusters
|
| Direction |
Input
|
| Level |
MEDIUM
|
| Description | The minimum number of documents that must be assigned to a cluster before the clustering engine attempts to create subclusters for that cluster.
Performance impact: high |
| Required |
no
|
| Scope | Processing time |
| Value type |
java.lang.Integer
|
| Default value |
10
|
| Min value |
3
|
| Max value |
50
|
| Attribute builder |
Lingo3GAttributesDescriptor.AttributeBuilder#minClusterSizeForSubclusters()
|
| Key |
normalize-scores
|
| Direction |
Input
|
| Level |
ADVANCED
|
| Description | Cluster and label score normalization switch.
When switched on, the clustering engine will normalize cluster and label scores so that they fall in the 0.0 to 1.0 range. Performance impact: none Results impact: As the value of this parameter does not have any impact on the order and structure of clusters generated by the clustering engine, this switch will be useful only for applications that depend on absolute values of cluster or label scores. |
| Required |
no
|
| Scope | Processing time |
| Value type |
java.lang.Boolean
|
| Default value |
true
|
| Attribute builder |
Lingo3GAttributesDescriptor.AttributeBuilder#normalizeScores()
|
| Key |
precise-document-assignment-slop-multiplier
|
| Direction |
Input
|
| Level |
MEDIUM
|
| Description | Configures the level of proximity of words enforced by the 'Precise document assignment' setting. Please see the description of the 'Precise document assignment' attribute for details. |
| Required |
no
|
| Scope | Processing time |
| Value type |
java.lang.Double
|
| Default value |
1.5
|
| Min value |
1.0
|
| Max value |
10.0
|
| Attribute builder |
Lingo3GAttributesDescriptor.AttributeBuilder#preciseDocumentAssignmentSlopMultiplier()
|
| Key |
precise-document-assignment-slop-offset
|
| Direction |
Input
|
| Level |
MEDIUM
|
| Description | Configures the level of proximity of words enforced by the 'Precise document assignment' setting. Please see the description of the 'Precise document assignment' attribute for details. |
| Required |
no
|
| Scope | Processing time |
| Value type |
java.lang.Integer
|
| Default value |
0
|
| Min value |
0
|
| Max value |
10
|
| Attribute builder |
Lingo3GAttributesDescriptor.AttributeBuilder#preciseDocumentAssignmentSlopOffset()
|
| Key |
precise-document-assignment
|
| Direction |
Input
|
| Level |
BASIC
|
| Description | When precise document assignment is switched off, clusters with multi word labels will contain all documents that contain the label's word in any order and at any position.
When precise document assignment is switched on, only documents containing all cluster label's words close to each other (but still in any order) will be placed in the cluster. The level of proximity between words enforced by this setting can be configured by the 'Precise document assignment slop multiplier' and 'Precise document assignment slop offset' attributes. The window in which all label words must occur in the document is defined as follows: Performance impact: medium |
| Required |
no
|
| Scope | Processing time |
| Value type |
java.lang.Boolean
|
| Default value |
false
|
| Attribute builder |
Lingo3GAttributesDescriptor.AttributeBuilder#preciseDocumentAssignment()
|
| Key |
reload-resources
|
| Direction |
Input
|
| Level |
BASIC
|
| Description | Forced resources reload switch.
Causes the clustering engine to reload lexical resources (stopwords, label dictionaries, synonyms etc.) on every clustering request. This is a debug-only switch, particularly useful when tuning lexical resources. When running Lingo3G within Lingo3G Workbench, the lexical resources are loaded from the Performance impact: very high. Make sure resource reloading is switched off in production settings. |
| Required |
no
|
| Scope | Processing time |
| Value type |
java.lang.Boolean
|
| Default value |
false
|
| Attribute builder |
Lingo3GAttributesDescriptor.AttributeBuilder#reloadResources()
|
| Key |
documents
|
| Direction |
Input
|
| Level |
BASIC
|
| Description | Documents to cluster. |
| Required |
yes
|
| Scope | Processing time |
| Value type |
java.util.List
|
| Default value | none |
| Attribute builder |
Lingo3GClusteringAlgorithmDescriptor.AttributeBuilder#_documents()
|
| Key |
dashed-words-label-filter
|
| Direction |
Input
|
| Level |
MEDIUM
|
| Description | Filters out labels containing words starting or ending in a dash character ('-').
Performance impact: low |
| Required |
no
|
| Scope | Processing time |
| Value type |
java.lang.Boolean
|
| Default value |
true
|
| Attribute builder |
Lingo3GAttributesDescriptor.AttributeBuilder#dashedWordsLabelFilter()
|
| Key |
dictionary-label-filter
|
| Direction |
Input
|
| Level |
MEDIUM
|
| Description | Removes or boosts labels based on a predefined dictionary of words, phrases and regular expressions.
Impact on performance depends on the number of regular expression entries in the label dictionary -- the more regular expression entries, the lower the processing speed. Performance impact: medium to very high |
| Required |
no
|
| Scope | Processing time |
| Value type |
java.lang.Boolean
|
| Default value |
true
|
| Attribute builder |
Lingo3GAttributesDescriptor.AttributeBuilder#dictionaryLabelFilter()
|
| Key |
label-dictionary
|
| Direction |
Input
|
| Level |
ADVANCED
|
| Description | Label dictionary.
Ad-hoc extra label dictionary that can be provided during clustering time. The dictionary needs to be an XML string or an array/list of XML strings in the same format as the built-in label dictionary. When multiple dictionaries are provided and a label matches entries from more than one dictionary (including the built-in one), the entry with the maximum weight will be applied, unless any of the entries sets the weight to 0, in which case the zero weight will apply. |
| Required |
no
|
| Scope | Processing time |
| Value type |
java.lang.Object
|
| Default value | none |
| Allowed value types |
Allowed value types:
|
| Attribute builder |
Lingo3GAttributesDescriptor.AttributeBuilder#labelDictionary()
|
| Key |
left-complete-label-filter
|
| Direction |
Input
|
| Level |
ADVANCED
|
| Description | Truncated labels filter.
Heuristically eliminates truncated cluster labels (e.g. "York Restaurants"), replacing them with complete phrases, e.g. "New York Restaurants", based on the context. It is recommended to use this filter in combination with 'Right complete label filter' . Strength of truncated label elimination determined by the 'Label override threshold' parameter. Performance impact: medium |
| Required |
no
|
| Scope | Processing time |
| Value type |
java.lang.Boolean
|
| Default value |
true
|
| Attribute builder |
Lingo3GAttributesDescriptor.AttributeBuilder#leftCompleteLabelFilter()
|
| Key |
min-length-label-filter
|
| Direction |
Input
|
| Level |
MEDIUM
|
| Description | Filters out labels whose string representation (excluding spaces) is shorter than 3 characters.
Performance impact: low |
| Required |
no
|
| Scope | Processing time |
| Value type |
java.lang.Boolean
|
| Default value |
true
|
| Attribute builder |
Lingo3GAttributesDescriptor.AttributeBuilder#minLengthLabelFilter()
|
| Key |
number-only-label-filter
|
| Direction |
Input
|
| Level |
MEDIUM
|
| Description | Filters out labels that consist only of numeric tokens.
Performance impact: low |
| Required |
no
|
| Scope | Processing time |
| Value type |
java.lang.Boolean
|
| Default value |
true
|
| Attribute builder |
Lingo3GAttributesDescriptor.AttributeBuilder#numberOnlyLabelFilter()
|
| Key |
one-letter-word-label-filter
|
| Direction |
Input
|
| Level |
MEDIUM
|
| Description | Filters out labels containing only one-letter words, e.g. "M a f".
Performance impact: low |
| Required |
no
|
| Scope | Processing time |
| Value type |
java.lang.Boolean
|
| Default value |
true
|
| Attribute builder |
Lingo3GAttributesDescriptor.AttributeBuilder#oneLetterWordLabelFilter()
|
| Key |
repeated-words-label-filter
|
| Direction |
Input
|
| Level |
MEDIUM
|
| Description | Filters out labels containing repeated words (e.g."New York York").
Performance impact: low |
| Required |
no
|
| Scope | Processing time |
| Value type |
java.lang.Boolean
|
| Default value |
false
|
| Attribute builder |
Lingo3GAttributesDescriptor.AttributeBuilder#repeatedWordsLabelFilter()
|
| Key |
right-complete-label-filter
|
| Direction |
Input
|
| Level |
ADVANCED
|
| Description | Truncated labels filter.
Heuristically eliminates truncated cluster labels (e.g. "York Restaurants"), replacing them with complete phrases, e.g. "New York Restaurants", based on the context. It is recommended to use this filter in combination with 'Left complete label filter' . Strength of truncated label elimination is determined by the 'Label override threshold' parameter. Performance impact: medium |
| Required |
no
|
| Scope | Processing time |
| Value type |
java.lang.Boolean
|
| Default value |
true
|
| Attribute builder |
Lingo3GAttributesDescriptor.AttributeBuilder#rightCompleteLabelFilter()
|
| Key |
trailing-genitive-label-filter
|
| Direction |
Input
|
| Level |
MEDIUM
|
| Description | Filters out phrases ending in Saxon genitive of an English noun, e.g. "Discover World's", "For your computers'".
Performance impact: low |
| Required |
no
|
| Scope | Processing time |
| Value type |
java.lang.Boolean
|
| Default value |
true
|
| Attribute builder |
Lingo3GAttributesDescriptor.AttributeBuilder#trailingGenitiveLabelFilter()
|
| Key |
word-dictionary
|
| Direction |
Input
|
| Level |
ADVANCED
|
| Description | Label dictionary. Ad-hoc extra word dictionary that can be provided during clustering time. The dictionary needs to be an XML string or an array/list of XML strings in the same format as the built-in word dictionary. When multiple dictionaries are provided, the dictionaries at lower indexes of the array/list take precedence. Ad-hoc dictionaries take precedence over the static dictionaries. |
| Required |
no
|
| Scope | Processing time |
| Value type |
java.lang.Object
|
| Default value | none |
| Allowed value types |
Allowed value types:
|
| Attribute builder |
Lingo3GAttributesDescriptor.AttributeBuilder#wordDictionary()
|
| Key |
capitalized-word-label-scorer-weight
|
| Direction |
Input
|
| Level |
ADVANCED
|
| Description | Assigns higher scores to labels that contain capitalized words.
Performance impact: low |
| Required |
no
|
| Scope | Processing time |
| Value type |
java.lang.Double
|
| Default value |
0.1
|
| Min value |
0.0
|
| Max value |
1.0
|
| Attribute builder |
Lingo3GAttributesDescriptor.AttributeBuilder#capitalizedWordLabelScorerWeight()
|
| Key |
dictionary-weight-label-scorer-weight
|
| Direction |
Input
|
| Level |
ADVANCED
|
| Description | Boosts label scores by a factor specified in the label dictionary file.
If this scorer has weight 0, label boosting will not be applied. Performance impact: low |
| Required |
no
|
| Scope | Processing time |
| Value type |
java.lang.Double
|
| Default value |
1.0
|
| Min value |
0.0
|
| Max value |
1.0
|
| Attribute builder |
Lingo3GAttributesDescriptor.AttributeBuilder#dictionaryWeightLabelScorerWeight()
|
| Key |
grammatical-variant-label-scorer-weight
|
| Direction |
Input
|
| Level |
ADVANCED
|
| Description | Strength of penalization of the less frequent variants of stem-equivalent labels.
For example, if the input documents contain phrases "Fuel efficiency" and "Fuel efficient", the less frequent phrase variant will be less likely to appear as a cluster label. When the value of this attribute is 1.0, the less frequent phrases will be penalized proportionally to the difference between the frequency of that phrase and the most frequent variant. Lower values of this attribute will decrease the penalty, setting the value to 0.0 will cause Lingo3G to treat all grammatical variants equally. Performance impact: low |
| Required |
no
|
| Scope | Processing time |
| Value type |
java.lang.Double
|
| Default value |
1.0
|
| Min value |
0.0
|
| Max value |
1.0
|
| Attribute builder |
Lingo3GAttributesDescriptor.AttributeBuilder#grammaticalVariantLabelScorerWeight()
|
| Key |
query-word-label-scorer-weight
|
| Direction |
Input
|
| Level |
ADVANCED
|
| Description | Penalizes labels that contain query words.
Performance impact: low |
| Required |
no
|
| Scope | Processing time |
| Value type |
java.lang.Double
|
| Default value |
0.1
|
| Min value |
0.0
|
| Max value |
1.0
|
| Attribute builder |
Lingo3GAttributesDescriptor.AttributeBuilder#queryWordLabelScorerWeight()
|
| Key |
tf-df-ratio-label-scorer-weight
|
| Direction |
Input
|
| Level |
ADVANCED
|
| Description | Assigns higher score to more general/shorter labels.
Performance impact: low |
| Required |
no
|
| Scope | Processing time |
| Value type |
java.lang.Double
|
| Default value |
0.2
|
| Min value |
0.0
|
| Max value |
1.0
|
| Attribute builder |
Lingo3GAttributesDescriptor.AttributeBuilder#tfDfRatioLabelScorerWeight()
|
| Key |
title-word-label-scorer-weight
|
| Direction |
Input
|
| Level |
ADVANCED
|
| Description | Assigns higher scores to labels that contain word that appeared in input documents' titles.
Performance impact: low |
| Required |
no
|
| Scope | Processing time |
| Value type |
java.lang.Double
|
| Default value |
0.6
|
| Min value |
0.0
|
| Max value |
1.0
|
| Attribute builder |
Lingo3GAttributesDescriptor.AttributeBuilder#titleWordLabelScorerWeight()
|
| Key |
unindexed-word-label-scorer-weight
|
| Direction |
Input
|
| Level |
ADVANCED
|
| Description | Penalizes labels that contain too many function words.
Performance impact: low |
| Required |
no
|
| Scope | Processing time |
| Value type |
java.lang.Double
|
| Default value |
0.1
|
| Min value |
0.0
|
| Max value |
1.0
|
| Attribute builder |
Lingo3GAttributesDescriptor.AttributeBuilder#unindexedWordLabelScorerWeight()
|
| Key |
word-count-label-scorer-weight
|
| Direction |
Input
|
| Level |
ADVANCED
|
| Description | Assigns higher scores to labels that consist of 2, 3 or 4 words.
Longer labels are penalized -- the longer the label, the higher the penalty. Performance impact: low |
| Required |
no
|
| Scope | Processing time |
| Value type |
java.lang.Double
|
| Default value |
1.0
|
| Min value |
0.0
|
| Max value |
1.0
|
| Attribute builder |
Lingo3GAttributesDescriptor.AttributeBuilder#wordCountLabelScorerWeight()
|
| Key |
cluster-count-base
|
| Direction |
Input
|
| Level |
BASIC
|
| Description | The number of clusters discovered in each clustering pass.
The higher the value of this parameter, the larger the total number of clusters. Performance impact: medium |
| Required |
no
|
| Scope | Processing time |
| Value type |
java.lang.Integer
|
| Default value |
7
|
| Min value |
2
|
| Max value |
100
|
| Attribute builder |
Lingo3GAttributesDescriptor.AttributeBuilder#clusterCountBase()
|
| Key |
document-coverage-target
|
| Direction |
Input
|
| Level |
BASIC
|
| Description | The percentage of input documents to be put in clusters.
Determines the percentage of documents the clustering engine should assign to clusters. After each clustering pass, the clustering engine will check if the required document coverage has been achieved. If so, it will not perform further clustering passes. The required document coverage may not always be achieved, especially if the maximum number of clustering passes is set to a low value. To cause the clustering engine to always perform the maximum number of clustering passes, set the value of this parameter to 1.0. Performance impact: high |
| Required |
no
|
| Scope | Processing time |
| Value type |
java.lang.Double
|
| Default value |
0.95
|
| Min value |
0.0
|
| Max value |
1.0
|
| Attribute builder |
Lingo3GAttributesDescriptor.AttributeBuilder#documentCoverageTarget()
|
| Key |
max-hierarchy-depth
|
| Direction |
Input
|
| Level |
MEDIUM
|
| Description | The maximum number of cluster levels to create.
Setting this parameter to 1 will disable hierarchical clustering. In such case it is also recommended to disable hierarchical merging, which will preserve smaller clusters. Performance impact: high |
| Required |
no
|
| Scope | Processing time |
| Value type |
java.lang.Integer
|
| Default value |
2
|
| Min value |
1
|
| Max value |
5
|
| Attribute builder |
Lingo3GAttributesDescriptor.AttributeBuilder#maxHierarchyDepth()
|
| Key |
max-improvement-iterations
|
| Direction |
Input
|
| Level |
ADVANCED
|
| Description | The number of clustering improvement iterations to perform.
Determines the maximum number of clustering improvement cycles the clustering engine should perform. During each cycle, it will examine clusterings similar to the current one, and if any of them is better, the current cluster arrangement will be replaced. Performance impact: very high |
| Required |
no
|
| Scope | Processing time |
| Value type |
java.lang.Integer
|
| Default value |
5
|
| Min value |
0
|
| Max value |
50
|
| Attribute builder |
Lingo3GAttributesDescriptor.AttributeBuilder#maxImprovementIterations()
|
| Key |
max-clustering-passes-sub
|
| Direction |
Input
|
| Level |
MEDIUM
|
| Description | Maximum number of clustering passes to perform on subclusters.
Determines the maximum number of cluster discovery passes the clustering engine should perform to discover subclusters. The first clustering pass discovers large/more general clusters, while further passes find smaller/more specific clusters. Setting the maximum number of passes to 0 will force the algorithm to stop clustering only when no more subclusters can be created or the 'Document coverage target' has been reached for the parent cluster. Performance impact: high Results impact: With the lowest value of this parameter, the clustering engine will discover only the largest clusters, while with higher values, smaller and more specific clusters will also be created. Setting this parameter to 0 will cause the clustering algorithm to create the maximum possible number of subclusters for each cluster. |
| Required |
no
|
| Scope | Processing time |
| Value type |
java.lang.Integer
|
| Default value |
2
|
| Min value |
0
|
| Max value |
10
|
| Attribute builder |
Lingo3GAttributesDescriptor.AttributeBuilder#maxClusteringPassesSub()
|
| Key |
max-clustering-passes-top
|
| Direction |
Input
|
| Level |
BASIC
|
| Description | Maximum number of clustering passes to perform on top hierarchy level.
Determines the maximum number of cluster discovery passes the clustering engine should perform to discover the top-level clusters. The first clustering pass discovers large/more general clusters, while further passes find smaller/more specific clusters. Setting the maximum number of passes to 0 will force the algorithm to stop clustering only when no more clusters can be created or the 'Document coverage target' has been reached. Performance impact: high Results impact: With the lowest value of this parameter, the clustering engine will discover only the largest clusters, while with higher values, smaller and more specific clusters will also be created. Setting this parameter to 0 will cause the clustering algorithm to create the maximum possible number of clusters. |
| Required |
no
|
| Scope | Processing time |
| Value type |
java.lang.Integer
|
| Default value |
4
|
| Min value |
0
|
| Max value |
10
|
| Attribute builder |
Lingo3GAttributesDescriptor.AttributeBuilder#maxClusteringPassesTop()
|
| Key |
neighborhood-size
|
| Direction |
Input
|
| Level |
ADVANCED
|
| Description | Maximum similar clusterings to examine.
Determines the maximum number of similar clusterings the clustering engine should examine during each improvement cycle. This parameter is meaningful only when 'Maximum improvement iterations' is greater than 0. Performance impact: very high |
| Required |
no
|
| Scope | Processing time |
| Value type |
java.lang.Integer
|
| Default value |
20
|
| Min value |
10
|
| Max value |
200
|
| Attribute builder |
Lingo3GAttributesDescriptor.AttributeBuilder#neighborhoodSize()
|
| Key |
unknown-word-handling-strategy
|
| Direction |
Input
|
| Level |
ADVANCED
|
| Description | Handling of unknown words in persistent clusters.
Defines how Lingo3G should treat unknown words in labels of persistent clusters. A word is unknown when it occurs in the persistent cluster's label but it is not present in any of the documents being clustered. The two available options are:
Performance impact: none |
| Required |
no
|
| Scope | Processing time |
| Value type |
com.carrotsearch.lingo3g.Lingo3GAttributes$UnknownWordHandlingStrategy
|
| Default value |
DO_NOT_ASSIGN_DOCUMENTS
|
| Allowed values |
|
| Attribute builder |
Lingo3GAttributesDescriptor.AttributeBuilder#unknownWordHandlingStrategy()
|
| Key |
allow-numbers-in-labels
|
| Direction |
Input
|
| Level |
BASIC
|
| Description | Allow numbers in labels switch.
When switched on, the clustering engine will allow numbers to appear in cluster labels. Performance impact: low |
| Required |
no
|
| Scope | Processing time |
| Value type |
java.lang.Boolean
|
| Default value |
true
|
| Attribute builder |
Lingo3GAttributesDescriptor.AttributeBuilder#allowNumbersInLabels()
|
| Key |
capitalize-non-function-words
|
| Direction |
Input
|
| Level |
MEDIUM
|
| Description | Capitalize non function words in labels.
When switched on, the clustering engine will capitalize all non function words in labels. When switched off, particular words will appear in labels in the case they appeared in the majority of input documents. Performance impact: low |
| Required |
no
|
| Scope | Processing time |
| Value type |
java.lang.Boolean
|
| Default value |
true
|
| Attribute builder |
Lingo3GAttributesDescriptor.AttributeBuilder#capitalizeNonFunctionWords()
|
| Key |
label-override-threshold
|
| Direction |
Input
|
| Level |
ADVANCED
|
| Description | Determines the strength of the truncated label filters.
The lowest value means strongest truncated labels elimination, which may lead to overlong cluster labels and many unclustered documents. The highest value effectively disables the filter, which may result in short or truncated labels. Performance impact: low |
| Required |
no
|
| Scope | Processing time |
| Value type |
java.lang.Double
|
| Default value |
0.5
|
| Min value |
0.2
|
| Max value |
1.0
|
| Attribute builder |
Lingo3GAttributesDescriptor.AttributeBuilder#labelOverrideThreshold()
|
| Key |
lowercase-function-words
|
| Direction |
Input
|
| Level |
MEDIUM
|
| Description | Use lower case for function words in labels.
When switched on, the clustering engine will convert all function words in labels into lower case. When switched off, particular function words will appear in labels in the case they appeared in the majority of input documents. Performance impact: low |
| Required |
no
|
| Scope | Processing time |
| Value type |
java.lang.Boolean
|
| Default value |
true
|
| Attribute builder |
Lingo3GAttributesDescriptor.AttributeBuilder#lowercaseFunctionWords()
|
| Key |
max-label-words
|
| Direction |
Input
|
| Level |
MEDIUM
|
| Description | Determines the maximum label length in words.
Labels consisting of more words will not be generated. Performance impact: none Results impact: Setting the maximum label length to some lower value (e.g. 2 or 3) may create more general clusters. This setting can also be useful when the input collection contains duplicate documents. In such cases, Lingo3G may create overlong cluster labels taken directly from the duplicate documents. While the best solution to this problem would be eliminating duplicate documents from input, lowering the maximum label length can serve as a simple workaround. |
| Required |
no
|
| Scope | Processing time |
| Value type |
java.lang.Integer
|
| Default value |
8
|
| Min value |
1
|
| Max value |
8
|
| Attribute builder |
Lingo3GAttributesDescriptor.AttributeBuilder#maxLabelWords()
|
| Key |
min-label-words
|
| Direction |
Input
|
| Level |
MEDIUM
|
| Description | Determines the minimum label length in words.
Labels consisting of fewer words will not be generated. Performance impact: none Results impact: Setting the minimum label length to some higher value (e.g. 4 or 5) may create more specific clusters. |
| Required |
no
|
| Scope | Processing time |
| Value type |
java.lang.Integer
|
| Default value |
1
|
| Min value |
1
|
| Max value |
8
|
| Attribute builder |
Lingo3GAttributesDescriptor.AttributeBuilder#minLabelWords()
|
| Key |
preferred-label-length-deviation
|
| Direction |
Input
|
| Level |
MEDIUM
|
| Description | Allowed deviation from the preferred label length.
Determines how far the clustering engine is allowed to deviate from the com.carrotsearch.lingo3g.Lingo3GAttributes.preferredLabelLength. A value of 0.0 allows no deviation: all labels must have the preferred length. Larger values allow more and more deviation, with the value of 20.0 meaning almost no preference at all. When the preferred label length deviation is 0.0 and the fractional part of the preferred label length is 0.5, then the only allowed label lengths will be the two integers closest to the preferred label length value. For example, if preferred label length deviation is 0.0 and preferred label length is 2.5, the clustering engine will create only labels consisting of 2 or 3 words. If the fractional part of the preferred label length is other than 0.5, only the closest integer label length will be preferred. Performance impact: none |
| Required |
no
|
| Scope | Processing time |
| Value type |
java.lang.Double
|
| Default value |
2.5
|
| Min value |
0.0
|
| Max value |
20.0
|
| Attribute builder |
Lingo3GAttributesDescriptor.AttributeBuilder#preferredLabelLengthDeviation()
|
| Key |
preferred-label-length
|
| Direction |
Input
|
| Level |
MEDIUM
|
| Description | Instructs the clustering engine to prefer cluster labels consisting of the specified number of words.
The strength of the preference is determined by the com.carrotsearch.lingo3g.Lingo3GAttributes.preferredLabelLengthDeviation attribute. Fractional preferred label lengths are also allowed. For example, preferred label length of 2.5 will result in labels of length 2 and 3 being treated equally preferred; a value of 2.2 will prefer two-word labels more than three-word ones. Performance impact: none |
| Required |
no
|
| Scope | Processing time |
| Value type |
java.lang.Double
|
| Default value |
2.5
|
| Min value |
0.0
|
| Max value |
8.0
|
| Attribute builder |
Lingo3GAttributesDescriptor.AttributeBuilder#preferredLabelLength()
|
| Key |
put-promoted-labels-at-hierarchy-root
|
| Direction |
Input
|
| Level |
MEDIUM
|
| Description | Put promoted labels at hierarchy root.
When switched on, labels promoted using the label dictionary will be always put at the top level of the cluster hierarchy. When switched off, promoted labels will not be forced to appear at the hierarchy root and will be placed where they naturally belong, e.g. as subclusters of larger clusters. Results impact: a lot of labels can get promoted as a result of boosting e.g. proper nouns defined in the built-in POS database. With this option enabled, all such labels will be put at the root of cluster hierarchy, which may result in a clearly visible cluster overlap. For example, clusters Bill Clinton, President Bill Clinton and U.S. President Bill Clinton will all show at the root of the cluster tree, while with this option disabled, only the Bill Clinton cluster would be placed at root of the hierarchy. Performance impact: low |
| Required |
no
|
| Scope | Processing time |
| Value type |
java.lang.Boolean
|
| Default value |
false
|
| Attribute builder |
Lingo3GAttributesDescriptor.AttributeBuilder#putPromotedLabelsAtHierarchyRoot()
|
| Key |
query-word-label-weight
|
| Direction |
Input
|
| Level |
ADVANCED
|
| Description | Determines the weight of labels containing query words.
Lower values mean that phrases containing query words are less likely to appear as cluster labels. In particular, the value of 0.0 will totally eliminate query words from cluster labels. The value of 1.0, on the other hand, will cause the clustering engine to treat equally labels with and without query words. Performance impact: low |
| Required |
no
|
| Scope | Processing time |
| Value type |
java.lang.Double
|
| Default value |
0.5
|
| Min value |
0.0
|
| Max value |
1.0
|
| Attribute builder |
Lingo3GAttributesDescriptor.AttributeBuilder#queryWordLabelWeight()
|
| Key |
remove-repeated-synonyms-from-labels
|
| Direction |
Input
|
| Level |
MEDIUM
|
| Description | Remove repeated synonyms from labels.
When switched on, no synonymous words will appear in a single label. For example, if 'photos' and 'pictures' are declared synonyms, labels such as 'Tiger Photos Pictures" or "Photos and Pictures" will not be generated. Performance impact: low |
| Required |
no
|
| Scope | Processing time |
| Value type |
java.lang.Boolean
|
| Default value |
true
|
| Attribute builder |
Lingo3GAttributesDescriptor.AttributeBuilder#removeRepeatedSynonymsFromLabels()
|
| Key |
single-word-label-weight
|
| Direction |
Input
|
| Level |
BASIC
|
| Description | Determines how willing the clustering engine will be to select single words as cluster labels.
The higher the value of this parameter, the more clusters described with single-word labels will be produced. Performance impact: none |
| Required |
no
|
| Scope | Processing time |
| Value type |
java.lang.Double
|
| Default value |
0.5
|
| Min value |
0.0
|
| Max value |
1.0
|
| Attribute builder |
Lingo3GAttributesDescriptor.AttributeBuilder#singleWordLabelWeight()
|
| Key |
accent-folding
|
| Direction |
Input
|
| Level |
MEDIUM
|
| Description | Converts national characters to ASCII counterparts.
When accent folding is switched on, all national characters (e.g. 'ü', 'ç', 'ó') will be internally replaced with their ASCII counterparts ('u', 'c', 'o'), which will make e.g. the words "Bücher" and "Bucher" equivalent. Please note that this is an instance-level parameter and changes of its value at request time will not be respected. Performance impact: high |
| Required |
no
|
| Scope | Initialization time |
| Value type |
java.lang.Boolean
|
| Default value |
true
|
| Attribute builder |
Lingo3GAttributesDescriptor.AttributeBuilder#accentFolding()
|
| Key |
japanese-allow-subphrase-labels
|
| Direction |
Input
|
| Level |
ADVANCED
|
| Description | Allow sub-phrase cluster labels.
Applies to Japanese only. Performance impact: high. |
| Required |
no
|
| Scope | Initialization time and Processing time |
| Value type |
java.lang.Boolean
|
| Default value |
false
|
| Attribute builder |
Lingo3GAttributesDescriptor.AttributeBuilder#japaneseAllowSubphraseLabels()
|
| Key |
use-built-in-word-database-for-label-filtering
|
| Direction |
Input
|
| Level |
ADVANCED
|
| Description | Use built-in word database for label filtering.
If enabled, Lingo3G will perform label filtering based on the the built-in word databases in addition to the word dictionary XML files. Currently, a built-in word database is available only for the English language. Results impact: If this option is enabled, Lingo3G should produce better-formed cluster labels. For example, labels being, starting or ending with a verb or adjective should appear less frequently. However, because of the limitations of the current part of speech tagging model (please see below), enabling this option is also likely to prevent certain well-formed cluster labels, e.g. if the built-in word database misinterprets a noun for a verb. Limitations of the part of speech tagging model. Currently, Lingo3G uses a unigram model for assigning part of speech tags to words. This means that for each word having multiple part of speech tags (such as "program" in English, which, depending on the context, can be both a verb and a noun), one of the available tags needs to be chosen. To do that, Lingo3G employs a heuristic that takes into account the word frequency and the set of part of speech tags the word has. While the heuristic is fairly efficient in a general, some words may be tagged erroneously. To provide a solution for such cases, the built-in part of speech database tags can be overridden in the user-defined XML word dictionary. Performance impact: small. |
| Required |
no
|
| Scope | Processing time |
| Value type |
java.lang.Boolean
|
| Default value |
true
|
| Attribute builder |
Lingo3GAttributesDescriptor.AttributeBuilder#useBuiltInWordDatabaseForLabelFiltering()
|
| Key |
use-built-in-word-database-for-stemming
|
| Direction |
Input
|
| Level |
ADVANCED
|
| Description | Use built-in word database for stemming.
If enabled, Lingo3G will use the word inflection database rather than an algorithmic stemmer. Currently, word inflection database is available only for the English language. Stemmers or word inflection databases transform various form of a word to one common root. This is required to make sure that a cluster labeled e.g. Programming contains documents referencing all variants of the word, such as programs, programmer or programmed. Results impact: Algorithmic stemming tends to be more aggressive compared to stemming based on word inflection dictionaries shipping with Lingo3G. This means that with algorithmic stemming all the following forms: program, programming, programmer and programmable will be treated as the same concept, while with the word database based stemming, they will be treated as separate, different concepts. As a result, with algorithmic stemming, a cluster labeled Program will contain documents referring to all program, programs, programming programmer and programmable, while with the word database based stemming, the cluster will contain only documents referring to program and programs. Enabling this option is recommended only when it is important do distinguish between slight variations of the same general concept, e.g. programming and program. Performance impact: small. |
| Required |
no
|
| Scope | Processing time |
| Value type |
java.lang.Boolean
|
| Default value |
false
|
| Attribute builder |
Lingo3GAttributesDescriptor.AttributeBuilder#useBuiltInWordDatabaseForStemming()
|
| Key |
content-fields
|
| Direction |
Input
|
| Level |
ADVANCED
|
| Description | Content fields to use for clustering.
Specifies the list of document field names that provide the content for clustering. As opposed to the title-fields attribute, fields provided in this attribute will not be given any extra weight during clustering. |
| Required |
no
|
| Scope | Processing time |
| Value type |
java.util.List
|
| Default value |
[snippet]
|
| Attribute builder |
Lingo3GAttributesDescriptor.AttributeBuilder#contentFields()
|
| Key |
label-token-delimiter
|
| Direction |
Input
|
| Level |
ADVANCED
|
| Description | Enforce a token delimiter in cluster labels other than the default.
By default the label delimiter is a whitespace (or nothing at all for CJK). Performance impact: none. |
| Required |
no
|
| Scope | Initialization time and Processing time |
| Value type |
java.lang.String
|
| Default value | none |
| Attribute builder |
Lingo3GAttributesDescriptor.AttributeBuilder#labelTokenDelimiter()
|
| Key |
language-recognition
|
| Direction |
Input
|
| Level |
MEDIUM
|
| Description | Language recognition switch.
When switched on, for those input documents that do not have the org.carrot2.core.Document.LANGUAGE field set, the clustering engine will attempt to recognize their language. If a document already has the org.carrot2.core.Document.LANGUAGE set, it will be used for further processing. Performance impact: low |
| Required |
no
|
| Scope | Processing time |
| Value type |
java.lang.Boolean
|
| Default value |
false
|
| Attribute builder |
Lingo3GAttributesDescriptor.AttributeBuilder#languageRecognition()
|
| Key |
max-tokens-per-document
|
| Direction |
Input
|
| Level |
MEDIUM
|
| Description | Maximum tokens per document to read.
Determines the maximum number of tokens (words) the clustering engine will read from each input document. When this parameter is set to 0, all tokens will be read. Performance impact: high |
| Required |
no
|
| Scope | Processing time |
| Value type |
java.lang.Integer
|
| Default value |
0
|
| Min value |
0
|
| Max value |
10000
|
| Attribute builder |
Lingo3GAttributesDescriptor.AttributeBuilder#maxTokensPerDocument()
|
| Key |
max-word-df
|
| Direction |
Input
|
| Level |
MEDIUM
|
| Description | Maximum word document frequency.
The maximum document frequency allowed for words as a fraction of all documents. Words with document frequency larger than maxWordDf will be ignored. For example, when maxWordDf is 0.4, words appearing in more than 40% of documents will be be ignored. A value of 1.0 means that all words will be taken into account, no matter in how many documents they appear. This attribute may be useful when certain words appear in most of the input documents (e.g. company name from header or footer) and such words dominate the cluster labels. In such case, setting maxWordDf to a value lower than 1.0, e.g. 0.9 may improve the clusters. Another useful application of this attribute is when there is a need to generate only very specific clusters, i.e. clusters containing small numbers of documents. This can be achieved by setting maxWordDf to extremely low values, e.g. 0.1 or 0.05. Performance impact: low |
| Required |
no
|
| Scope | Processing time |
| Value type |
java.lang.Double
|
| Default value |
1.0
|
| Min value |
0.0
|
| Max value |
1.0
|
| Attribute builder |
Lingo3GAttributesDescriptor.AttributeBuilder#maxWordDf()
|
| Key |
japanese-key-phrases-per-doc
|
| Direction |
Input
|
| Level |
ADVANCED
|
| Description | Number of key phrases per document.
Applies to Japanese only. Performance impact: high. |
| Required |
no
|
| Scope | Initialization time and Processing time |
| Value type |
java.lang.Integer
|
| Default value |
20
|
| Attribute builder |
Lingo3GAttributesDescriptor.AttributeBuilder#japaneseKeyPhrasesPerDoc()
|
| Key |
min-language-recognition-confidence
|
| Direction |
Input
|
| Level |
ADVANCED
|
| Description | Minimum language recognition confidence level to consider the input text to be written in a the most probable language.
The confidence is a probability-like value between 0 (not probable) and 1 (very probable). Performance impact: low |
| Required |
no
|
| Scope | Processing time |
| Value type |
java.lang.Double
|
| Default value |
0.4
|
| Min value |
0.0
|
| Max value |
1.0
|
| Attribute builder |
Lingo3GAttributesDescriptor.AttributeBuilder#minLanguageRecognitionConfidence()
|
| Key |
language-recognition-normalize-input
|
| Direction |
Input
|
| Level |
MEDIUM
|
| Description | Input normalization for language recognition. Marked as internal because we want this on the language identifier side. |
| Required |
no
|
| Scope | Processing time |
| Value type |
java.lang.Boolean
|
| Default value |
true
|
| Attribute builder |
Lingo3GAttributesDescriptor.AttributeBuilder#inputNormalizationForLanguageRecognition()
|
| Key |
phrase-df-threshold-scaling-factor
|
| Direction |
Input
|
| Level |
ADVANCED
|
| Description | Phrase-level Document Frequency (DF) cut-off scaling factor.
Determines how fast the phrase DF cut-off should grow with the increase of the number of documents. A value of 0.2 means that the phrase DF cut-off will increase by 0.2 per every 100 documents. Thus, for 100 documents the word DF cut-off will be 1.0, for 200 documents it will be 1.2, for 600 documents it will be 2.0 etc. Performance impact: very high Results impact: Setting low values for this parameter will preserve infrequent phrases, which can result in more accurate clustering (especially at subcluster level), at the cost of slower processing. Setting high values of this parameter will increase performance at the cost of lower clustering accuracy. |
| Required |
no
|
| Scope | Processing time |
| Value type |
java.lang.Double
|
| Default value |
0.2
|
| Min value |
0.0
|
| Max value |
5.0
|
| Attribute builder |
Lingo3GAttributesDescriptor.AttributeBuilder#phraseDfThresholdScalingFactor()
|
| Key |
title-fields
|
| Direction |
Input
|
| Level |
ADVANCED
|
| Description | Title fields to use for clustering.
Specifies the list of document field names that provide the content for clustering. Depending on the value of the title-word-label-scorer-weight attribute, content of fields provided in this attribute can be given more weight during clustering. |
| Required |
no
|
| Scope | Processing time |
| Value type |
java.util.List
|
| Default value |
[title]
|
| Attribute builder |
Lingo3GAttributesDescriptor.AttributeBuilder#titleFields()
|
| Key |
word-df-theshold-scaling-factor
|
| Direction |
Input
|
| Level |
ADVANCED
|
| Description | Word-level Document Frequency (DF) cut-off scaling factor.
Determines how fast the word DF cut-off should grow with the increase of the number of documents. A value of 1.0 means that the word DF cut-off will increase by 1.0 per every 100 documents. Thus, for 100 documents the word DF cut-off will be 1.0, for 200 documents it will be 2.0, for 350 documents it will be 3.5 etc. Performance impact: very high Results impact: Setting low values for this parameter will preserve infrequent words, which can result in more accurate clustering (especially at subcluster level), at the cost of slower processing. Setting high values of this parameter will increase performance at the cost of lower clustering accuracy. |
| Required |
no
|
| Scope | Processing time |
| Value type |
java.lang.Double
|
| Default value |
0.7
|
| Min value |
0.0
|
| Max value |
5.0
|
| Attribute builder |
Lingo3GAttributesDescriptor.AttributeBuilder#wordDfThesholdScalingFactor()
|
| Key |
license
|
| Direction |
Input
|
| Level |
ADVANCED
|
| Description | An explicit program license resource. By default, the license is sought in a set of default locations. This attribute provides an explicit license to be used. If this attribute has a non-null value, default locations are not scanned. |
| Required |
no
|
| Scope | Initialization time |
| Value type |
org.carrot2.util.resource.IResource
|
| Default value | none |
| Attribute builder |
Lingo3GAttributesDescriptor.AttributeBuilder#license()
|
| Key |
cluster-set-document-overlap-label-scorer-weight
|
| Direction |
Input
|
| Level |
ADVANCED
|
| Description | Assigns higher scores to labels that contain documents not present in the current cluster set.
Performance impact: low |
| Required |
no
|
| Scope | Processing time |
| Value type |
java.lang.Double
|
| Default value |
1.0
|
| Min value |
0.0
|
| Max value |
1.0
|
| Attribute builder |
Lingo3GAttributesDescriptor.AttributeBuilder#clusterSetDocumentOverlapLabelScorerWeight()
|
| Key |
cluster-scoring-fields
|
| Direction |
Input
|
| Level |
ADVANCED
|
| Description | Extra fields to use for cluster scoring.
If your input data contains structured data in addition to unstructured text, you can use the structured data to guide Lingo3G towards creating clusters having some specific properties. Usage scenario
For example, let us assume your data describes e-commerce products and has the following fields:
While Lingo3G will draw cluster labels from the unstructured text of the
Syntax Cluster scoring field specification has the following form:
where:
You can use commas to perform cluster scoring based on more than one field, e.g.:
You can specify the extra field in Carrot2 XML documents using the <document> <title>Canon 5D</title> <snippet>21MP camera</snippet> <url></url> <field key="price"><value type="java.lang.Double" value="149.90" /></field> <field key="votes"><value type="java.lang.Integer" value="4370" /></field> <field key="category"><value type="java.lang.String" value="Photo" /></field> </document> |
| Required |
no
|
| Scope | Processing time |
| Value type |
com.carrotsearch.lingo3g.Lingo3GAttributes$ClusterScoringFields
|
| Default value | none |
| Attribute builder |
Lingo3GAttributesDescriptor.AttributeBuilder#clusterScoringFields()
|
| Key |
document-count-label-scorer-weight
|
| Direction |
Input
|
| Level |
ADVANCED
|
| Description | Assigns higher scores to clusters whose number of documents in relation to the total number of documents is equal or smaller than specified by the 'Maximum cluster size' parameter.
Performance impact: low |
| Required |
no
|
| Scope | Processing time |
| Value type |
java.lang.Double
|
| Default value |
1.0
|
| Min value |
0.0
|
| Max value |
1.0
|
| Attribute builder |
Lingo3GAttributesDescriptor.AttributeBuilder#documentCountLabelScorerWeight()
|
| Key |
tf-label-scorer-weight
|
| Direction |
Input
|
| Level |
ADVANCED
|
| Description | Assigns higher scores to labels with higher Term Frequency (TF).
Performance impact: low |
| Required |
no
|
| Scope | Processing time |
| Value type |
java.lang.Double
|
| Default value |
1.0
|
| Min value |
0.0
|
| Max value |
1.0
|
| Attribute builder |
Lingo3GAttributesDescriptor.AttributeBuilder#tfLabelScorerWeight()
|
| Key |
aggressive-cloning-control
|
| Direction |
Input
|
| Level |
ADVANCED
|
| Description | Aggressive cluster cloning control switch.
When switched on, the clustering engine will not allow the same label to appear at any level of the hierarchy. This parameter is meaningful only if 'Cluster cloning control' is switched on. Performance impact: low |
| Required |
no
|
| Scope | Processing time |
| Value type |
java.lang.Boolean
|
| Default value |
false
|
| Attribute builder |
Lingo3GAttributesDescriptor.AttributeBuilder#aggressiveCloningControl()
|
| Key |
cloning-control
|
| Direction |
Input
|
| Level |
ADVANCED
|
| Description | Cluster cloning control switch.
When switched on, the clustering engine will not allow the same cluster label to appear both at the top- and subcluster-level of the hierarchy. Performance impact: low |
| Required |
no
|
| Scope | Processing time |
| Value type |
java.lang.Boolean
|
| Default value |
true
|
| Attribute builder |
Lingo3GAttributesDescriptor.AttributeBuilder#cloningControl()
|
| Key |
flat-merging
|
| Direction |
Input
|
| Level |
MEDIUM
|
| Description | Flat merging switch.
When switched on, the clustering engine will perform cluster merging using a strategy specific for flat (non-hierarchical) clusters. With this strategy the clustering engine will merge only clusters of similar size. Performance impact: low |
| Required |
no
|
| Scope | Processing time |
| Value type |
java.lang.Boolean
|
| Default value |
true
|
| Attribute builder |
Lingo3GAttributesDescriptor.AttributeBuilder#flatMerging()
|
| Key |
hierarchical-merging
|
| Direction |
Input
|
| Level |
MEDIUM
|
| Description | Hierarchical merging switch.
When switched on, the clustering engine will use a cluster merging strategy specially designed for hierarchical clustering, and will be more eager to move clusters from the top level positions to subclusters. If the algorithm is set to perform flat clustering (max-hierarchy-depth = 1), disabling hierarchical merging is recommended to preserve smaller clusters. Performance impact: low |
| Required |
no
|
| Scope | Processing time |
| Value type |
java.lang.Boolean
|
| Default value |
true
|
| Attribute builder |
Lingo3GAttributesDescriptor.AttributeBuilder#hierarchicalMerging()
|
| Key |
hierarchical-merging-with-labels
|
| Direction |
Input
|
| Level |
ADVANCED
|
| Description | Label merging switch.
When switched on, the clustering engine will take cluster labels into account while hierarchical merging of clusters. This parameter is meaningful only when 'Hierarchical merging' is switched on. Performance impact: low Results impact: With label merging switched on, the clustering engine may move some additional clusters from the top level to subclusters. |
| Required |
no
|
| Scope | Processing time |
| Value type |
java.lang.Boolean
|
| Default value |
true
|
| Attribute builder |
Lingo3GAttributesDescriptor.AttributeBuilder#hierarchicalMergingWithLabels()
|
| Key |
merge-threshold
|
| Direction |
Input
|
| Level |
MEDIUM
|
| Description | Cluster merge threshold.
If the overlap between clusters is larger than the value of this parameter, these clusters will be merged. Performance impact: none Results impact: Low values of this parameter will cause the clustering engine to eagerly merge clusters, which will create larger clusters in which some documents may be irrelevant. High values of this parameter will cause it to merge clusters rarely, which will result in large numbers of small clusters with more relevant documents. |
| Required |
no
|
| Scope | Processing time |
| Value type |
java.lang.Double
|
| Default value |
0.7
|
| Min value |
0.0
|
| Max value |
1.0
|
| Attribute builder |
Lingo3GAttributesDescriptor.AttributeBuilder#mergeThreshold()
|
| Key |
MultilingualClustering.defaultLanguage
|
| Direction |
Input
|
| Level |
MEDIUM
|
| Description | Default clustering language.
The default language to use for documents with undefined org.carrot2.core.Document.LANGUAGE. |
| Required |
yes
|
| Scope | Processing time |
| Value type |
org.carrot2.core.LanguageCode
|
| Default value |
ENGLISH
|
| Allowed values |
|
| Attribute builder |
MultilingualClusteringDescriptor.AttributeBuilder#defaultLanguage()
|
| Key |
MultilingualClustering.languageAggregationStrategy
|
| Direction |
Input
|
| Level |
MEDIUM
|
| Description | Language aggregation strategy.
Determines how clusters generated for individual languages should be combined to form the final result. Please see org.carrot2.text.clustering.MultilingualClustering.LanguageAggregationStrategy for the list of available options. |
| Required |
yes
|
| Scope | Processing time |
| Value type |
org.carrot2.text.clustering.MultilingualClustering$LanguageAggregationStrategy
|
| Default value |
FLATTEN_MAJOR_LANGUAGE
|
| Allowed values |
|
| Attribute builder |
MultilingualClusteringDescriptor.AttributeBuilder#languageAggregationStrategy()
|
| Key |
resource-lookup
|
| Direction |
Input
|
| Level |
ADVANCED
|
| Description | Lexical resource lookup facade. By default, resources are sought in the current thread's context class loader. An override of this attribute is possible both at the initialization time and at processing time. |
| Required |
no
|
| Scope | Initialization time and Processing time |
| Value type |
org.carrot2.util.resource.ResourceLookup
|
| Default value |
org.carrot2.util.resource.ResourceLookup
|
| Attribute builder |
Lingo3GAttributesDescriptor.AttributeBuilder#resourceLookup()
|
| Key |
PreprocessingPipeline.stemmerFactory
|
| Direction |
Input
|
| Level |
ADVANCED
|
| Description | Stemmer factory. Creates the stemmers to be used by the clustering algorithm. |
| Required |
no
|
| Scope | Initialization time |
| Value type |
org.carrot2.text.linguistic.IStemmerFactory
|
| Default value |
org.carrot2.text.linguistic.DefaultStemmerFactory
|
| Attribute builder |
Lingo3GAttributesDescriptor.AttributeBuilder#carrot2StemmerFactory()
|
| Key |
PreprocessingPipeline.tokenizerFactory
|
| Direction |
Input
|
| Level |
ADVANCED
|
| Description | Tokenizer factory. Creates the tokenizers to be used by the clustering algorithm (for selected languages which are delegated to C2 infrastructure). |
| Required |
no
|
| Scope | Initialization time |
| Value type |
org.carrot2.text.linguistic.ITokenizerFactory
|
| Default value |
org.carrot2.text.linguistic.DefaultTokenizerFactory
|
| Attribute builder |
Lingo3GAttributesDescriptor.AttributeBuilder#carrot2TokenizerFactory()
|
| Key |
query
|
| Direction |
Input
|
| Level |
BASIC
|
| Description | Query that produced the documents. The query will help the algorithm to create better clusters. Therefore, providing the query is optional but desirable. |
| Required |
no
|
| Scope | Processing time |
| Value type |
java.lang.String
|
| Default value | none |
| Attribute builder |
Lingo3GClusteringAlgorithmDescriptor.AttributeBuilder#query()
|
| Key |
clusters
|
| Direction |
Input
and
Output
|
| Level |
BASIC
|
| Description | Output clusters after processing or an empty list. |
| Required |
no
|
| Scope | Processing time |
| Value type |
java.util.List
|
| Default value | none |
| Attribute builder |
Lingo3GClusteringAlgorithmDescriptor.AttributeBuilder#_clusters()
|
| Key |
dashed-words-synonym-marker-enabled
|
| Direction |
Input
|
| Level |
MEDIUM
|
| Description | When switched on, the clustering engine will treat words separated by a space (' '), period ('.'), slash ('/') or a dash ('-') or written together and the corresponding phrases as synonymous, e.g. "data-mining", "data.mining", "datamining", "data/mining" and "data mining".
Performance impact: medium |
| Required |
no
|
| Scope | Processing time |
| Value type |
java.lang.Boolean
|
| Default value |
true
|
| Attribute builder |
Lingo3GAttributesDescriptor.AttributeBuilder#dashedWordsSynonymMarkerEnabled()
|
| Key |
dictionary-synonym-marker-enabled
|
| Direction |
Input
|
| Level |
MEDIUM
|
| Description | When switched on, the clustering engine will apply synonyms defined in the synonyms.[lang].xml file.
Performance impact: medium |
| Required |
no
|
| Scope | Processing time |
| Value type |
java.lang.Boolean
|
| Default value |
true
|
| Attribute builder |
Lingo3GAttributesDescriptor.AttributeBuilder#dictionarySynonymMarkerEnabled()
|
| Key |
synonym-dictionary
|
| Direction |
Input
|
| Level |
ADVANCED
|
| Description | Synonym dictionary. Ad-hoc extra synonym dictionary that can be provided during clustering time. The dictionary needs to be an XML string or an array/list of XML strings in the same format as the built-in synonym dictionary. Synonym definitions from all provided dictionaries as well as the static synonym dictionary will be merged. |
| Required |
no
|
| Scope | Processing time |
| Value type |
java.lang.Object
|
| Default value | none |
| Allowed value types |
Allowed value types:
|
| Attribute builder |
Lingo3GAttributesDescriptor.AttributeBuilder#synonymDictionary()
|
XML document source retrieves documents from local XML files or remote XML streams. It can optionally apply an XSLT transformation to convert the XML to the required format.
| Key |
documents
|
| Direction |
Output
|
| Description | Documents read from the XML data. |
| Scope | Processing time |
| Value type |
java.util.List
|
| Default value | none |
| Attribute builder |
XmlDocumentSourceDescriptor.AttributeBuilder#documents()
|
| Key |
query
|
| Direction |
Input
and
Output
|
| Level |
BASIC
|
| Description | After processing this field may hold the query read from the XML data, if any.
For the semantics of this field on input, see org.carrot2.source.xml.XmlDocumentSource.xml. |
| Required |
no
|
| Scope | Processing time |
| Value type |
java.lang.String
|
| Default value | none |
| Attribute builder |
XmlDocumentSourceDescriptor.AttributeBuilder#query()
|
| Key |
XmlDocumentSource.readAll
|
| Direction |
Input
|
| Level |
BASIC
|
| Description | If true, all documents are read from the input XML stream, regardless of the limit set by org.carrot2.source.xml.XmlDocumentSource.results.
|
| Required |
no
|
| Scope | Processing time |
| Value type |
java.lang.Boolean
|
| Default value |
true
|
| Attribute builder |
XmlDocumentSourceDescriptor.AttributeBuilder#readAll()
|
| Key |
results
|
| Direction |
Input
|
| Level |
BASIC
|
| Description | The maximum number of documents to read from the XML data if org.carrot2.source.xml.XmlDocumentSource.readAll is false.
The query hint can be used by clustering algorithms to avoid creating trivial clusters (combination of query words). |
| Required |
no
|
| Scope | Processing time |
| Value type |
java.lang.Integer
|
| Default value |
100
|
| Min value |
1
|
| Attribute builder |
XmlDocumentSourceDescriptor.AttributeBuilder#results()
|
| Key |
clusters
|
| Direction |
Input
and
Output
|
| Level |
BASIC
|
| Description | If org.carrot2.source.xml.XmlDocumentSource.readClusters is true and clusters are present in the input XML, they will be deserialized and exposed to components further down the processing chain.
|
| Required |
no
|
| Scope | Processing time |
| Value type |
java.util.List
|
| Default value | none |
| Attribute builder |
XmlDocumentSourceDescriptor.AttributeBuilder#clusters()
|
| Key |
processing-result.title
|
| Direction |
Output
|
| Description | The title (file name or query attribute, if present) for the search result fetched from the resource. A typical title for a processing result will be the query used to fetch documents from that source. For certain document sources the query may not be needed (on-disk XML, feed of syndicated news); in such cases, the input component should set its title properly for visual interfaces such as the workbench. |
| Scope | Processing time |
| Value type |
java.lang.String
|
| Default value | none |
| Attribute builder |
XmlDocumentSourceDescriptor.AttributeBuilder#title()
|
| Key |
XmlDocumentSourceHelper.timeout
|
| Direction |
Input
|
| Level |
ADVANCED
|
| Description | Data transfer timeout. Specifies the data transfer timeout, in seconds. A timeout value of zero is interpreted as an infinite timeout. |
| Required |
no
|
| Scope | Processing time |
| Value type |
java.lang.Integer
|
| Default value |
8
|
| Min value |
0
|
| Max value |
300
|
| Attribute builder |
XmlDocumentSourceHelperDescriptor.AttributeBuilder#timeout()
|
| Key |
XmlDocumentSource.xmlParameters
|
| Direction |
Input
|
| Level |
ADVANCED
|
| Description | Values for custom placeholders in the XML URL.
If the type of resource provided in the org.carrot2.source.xml.XmlDocumentSource.xml attribute is org.carrot2.util.resource.URLResourceWithParams, this map provides values for custom placeholders found in the XML URL. Keys of the map correspond to placeholder names, values of the map will be used to replace the placeholders. Please see org.carrot2.source.xml.XmlDocumentSource.xml for the placeholder syntax. |
| Required |
no
|
| Scope | Initialization time and Processing time |
| Value type |
java.util.Map
|
| Default value |
{}
|
| Attribute builder |
XmlDocumentSourceDescriptor.AttributeBuilder#xmlParameters()
|
| Key |
XmlDocumentSource.xml
|
| Direction |
Input
|
| Level |
BASIC
|
| Description | The resource to load XML data from.
You can either create instances of org.carrot2.util.resource.IResource implementations directly or use org.carrot2.util.resource.ResourceLookup to look up org.carrot2.util.resource.IResource instances from a variety of locations. One special
Additionally, custom placeholders can be used. Values for the custom placeholders should be provided in the |
| Required |
yes
|
| Scope | Initialization time and Processing time |
| Value type |
org.carrot2.util.resource.IResource
|
| Default value | none |
| Allowed value types | Allowed value types: Other assignable value types are allowed. |
| Attribute builder |
XmlDocumentSourceDescriptor.AttributeBuilder#xml()
|
| Key |
XmlDocumentSource.readClusters
|
| Direction |
Input
|
| Level |
BASIC
|
| Description | If clusters are present in the input XML they will be read and exposed to components further down the processing chain. |
| Required |
no
|
| Scope | Initialization time and Processing time |
| Value type |
java.lang.Boolean
|
| Default value |
false
|
| Attribute builder |
XmlDocumentSourceDescriptor.AttributeBuilder#readClusters()
|
| Key |
XmlDocumentSource.xsltParameters
|
| Direction |
Input
|
| Level |
ADVANCED
|
| Description | Parameters to be passed to the XSLT transformer. Keys of the map will be used as parameter names, values of the map as parameter values. |
| Required |
no
|
| Scope | Initialization time and Processing time |
| Value type |
java.util.Map
|
| Default value |
{}
|
| Attribute builder |
XmlDocumentSourceDescriptor.AttributeBuilder#xsltParameters()
|
| Key |
XmlDocumentSource.xslt
|
| Direction |
Input
|
| Level |
MEDIUM
|
| Description | The resource to load XSLT stylesheet from.
The XSLT stylesheet is optional and is useful when the source XML stream does not follow the Carrot2 format. The XSLT transformation will be applied to the source XML stream, the transformed XML stream will be deserialized into org.carrot2.core.Documents. The XSLT To pass additional parameters to the XSLT transformer, use the |
| Required |
no
|
| Scope | Initialization time and Processing time |
| Value type |
org.carrot2.util.resource.IResource
|
| Default value | none |
| Allowed value types | Allowed value types: Other assignable value types are allowed. |
| Attribute builder |
XmlDocumentSourceDescriptor.AttributeBuilder#xslt()
|
This section shows examples of Carrot2 input and output XML formats, used consistently by all Lingo3G applications, including Lingo3G Document Clustering Workbench, Lingo3G Document Clustering Server and Lingo3G Web Application.
To provide documents for Lingo3G clustering, use the following XML format:
Figure 10.1 Carrot2 input XML format
<?xml version="1.0" encoding="UTF-8"?>
<searchresult>
<query>Globe</query>
<document id="0">
<title>default</title>
<url>http://www.globe.com.ph/</url>
<snippet>
Provides mobile communications (GSM) including
GenTXT, handyphones, wireline services, an
broadband Internet services.
</snippet>
</document>
<document id="1">
<title>Skate Shoes by Globe | Time For Change</title>
<url>http://www.globeshoes.com/</url>
<snippet>
Skaters, surfers, and showboarders
designing in their own style.
</snippet>
</document>
...
</searchresult>
Lingo3G saves the clusters in the following XML format:
Figure 10.2 Carrot2 output XML format
<?xml version="1.0" encoding="UTF-8"?>
<searchresult>
<query>Globe</query>
<document id="0">
<title>default</title>
<url>http://www.globe.com.ph/</url>
<snippet>
Provides mobile communications (GSM) including
GenTXT, handyphones, wireline services, an
broadband Internet services.
</snippet>
</document>
<document id="1">
<title>Skate Shoes by Globe | Time For Change</title>
<url>http://www.globeshoes.com/</url>
<snippet>
Skaters, surfers, and showboarders
designing in their own style.
</snippet>
</document>
...
<group id="0" size="60" score="1.0">
<title>
<phrase>com</phrase>
</title>
<group id="1" size="2" score="1.0">
<title>
<phrase>amazon.com</phrase>
</title>
<document refid="43"/>
<document refid="77"/>
</group>
<group id="2" size="2" score="0.8">
<title>
<phrase>boston.com</phrase>
</title>
<document refid="4"/>
<document refid="7"/>
</group>
...
<group id="7" size="48">
<title>
<phrase>Other Sites</phrase>
</title>
<attribute key="other-topics">
<value type="java.lang.Boolean" value="true"/>
</attribute>
<document refid="1"/>
<document refid="2"/>
...
</group>
</group>
<group id="8" size="12" score="0.72">
<title>
<phrase>org</phrase>
</title>
<group id="9" size="2" score="1.0">
<title>
<phrase>en.wikipedia.org</phrase>
</title>
<document refid="9"/>
<document refid="14"/>
...
</group>
</group>
...
</searchresult>
This section shows examples of Carrot2 output JSON format, used consistently by all Lingo3G applications, including Lingo3G Document Clustering Server and Lingo3G Java API.
Lingo3G saves documents and the clusters in the following JSON format:
Figure 10.3 Carrot2 output JSON format
{
"clusters": [
{
"attributes": {
"score": 1.0
},
"documents": [
0,
2
],
"id": 0,
"phrases": [
"Cluster 1"
],
"score": 1.0,
"size": 2
},
{
"attributes": {
"score": 0.63
},
"clusters": [
{
"attributes": {
"score": 0.3
},
"documents": [
1
],
"id": 2,
"phrases": [
"Cluster 2.1"
],
"score": 0.3,
"size": 1
},
{
"attributes": {
"score": 0.15
},
"documents": [
2
],
"id": 3,
"phrases": [
"Cluster 2.2"
],
"score": 0.15,
"size": 1
}
],
"documents": [
0
],
"id": 1,
"phrases": [
"Cluster 2"
],
"score": 0.63,
"size": 3
}
],
"documents": [
{
"id": 0,
"snippet": "Document 1 Content.",
"title": "Document 1 Title",
"url": "http://document.url/1"
},
{
"id": 1,
"snippet": "Document 2 Content.",
"title": "Document 2 Title",
"url": "http://document.url/2"
},
{
"id": 2,
"snippet": "Document 3 Content.",
"title": "Document 3 Title",
"url": "http://document.url/3"
}
],
"query": "query (optional)"
}